





























Last Updated on septembre 13, 2022
Les dirigeants sous-estiment souvent le temps et les efforts nécessaires à la mise en place de l’informatique décisionnelle au sein d’une organisation. Ils pensent que c’est aussi simple que de rassembler des données de toutes les sources, de les réunir sur une feuille de calcul et de les transmettre à des outils de veille stratégique ou, encore plus simple, de faire appel à un analyste de données capable de produire de l’intelligence à partir de chiffres. À la fin du projet, ils s’attendent à recevoir des informations incroyables sur les performances de l’entreprise, les opportunités de marché potentielles et les prévisions de revenus pour la prochaine décennie.
Le processus de BI n’est pas si simple, et l’élément le plus critique pour sa réussite est souvent négligé : l’intégration des données. Pour que l’exploitation des données se déroule sans heurts dans une entreprise, celles-ci doivent d’abord être disponibles au bon endroit, au bon moment et dans le bon format. La dispersion des données – qui résident dans des silos – est la cause première de l’incohérence, de l’inefficacité et de l’inexactitude de vos efforts de veille stratégique et autres opérations sur les données.
Dans ce blog, nous allons apprendre ce qu’est l’intégration des données, et discuter de ses différents types, processus et outils. Commençons.
Qu’est-ce que l’intégration des données ?
L’intégration des données est définie comme suit :
Le processus de combinaison, de consolidation et de fusion de données provenant de multiples sources disparates afin d’obtenir une vue unique et uniforme des données et de permettre une gestion, une analyse et un accès efficaces aux données.
La capture et le stockage constituent la première étape du cycle de vie de la gestion des données. Mais des données disparates – résidant dans diverses bases de données, feuilles de calcul, serveurs locaux et applications tierces – ne sont d’aucune utilité tant qu’elles ne sont pas regroupées. L’intégration des données permet à votre entreprise d’appliquer de manière pratique et holistique les informations capturées et de répondre aux questions commerciales essentielles.
Prenons l’exemple de l’intégration des données clients. Dans toute organisation, les données clients sont stockées et hébergées à de multiples endroits – notamment dans les outils de suivi des sites web, les CRM, les logiciels d’automatisation du marketing et de comptabilité, etc. Pour donner du sens aux informations sur les clients et en extraire des informations utiles, votre équipe ne peut pas passer constamment d’une application à l’autre. Ils ont besoin d’un accès unique et uniforme aux enregistrements des données des clients – où les données sont propres et sans ambiguïté.
De même, il existe d’innombrables autres avantages de l’intégration des données qui permettent une gestion efficace des données, une veille économique et d’autres opérations sur les données.
5 types d’intégration de données
L’intégration des données peut être réalisée de plusieurs façons. Communément appelées méthodes, techniques, approches ou types d’intégration de données, il existe 5 façons différentes d’intégrer vos données.
1. Intégration de données par lots
Dans ce type d’intégration de données, les données passent par le processus ETL par lots à des moments programmés (hebdomadaires ou mensuels). Elles sont extraites de sources disparates, transformées en une vue cohérente et normalisée, puis chargées dans un nouveau magasin de données, tel qu’un entrepôt de données ou plusieurs marts de données. Cette intégration est surtout utile pour l’analyse des données et la veille stratégique, car un outil de veille stratégique ou une équipe d’analystes peut simplement observer les données stockées dans l’entrepôt.
2. Intégration des données en temps réel
Dans ce type d’intégration de données, les données entrantes ou en continu sont intégrées aux enregistrements existants en quasi temps réel par le biais de pipelines de données configurés. Les entreprises utilisent des pipelines de données pour automatiser le mouvement et la transformation des données, et les acheminer vers la destination ciblée. Les processus d’intégration des données entrantes (en tant que nouvel enregistrement ou mise à jour/application des informations existantes) sont intégrés dans le pipeline de données.

3. Consolidation des données
Dans ce type d’intégration de données, une copie de tous les ensembles de données sources est créée dans un environnement ou une application de transit, les enregistrements de données sont ensuite consolidés pour représenter une vue unique, puis finalement déplacés vers une source de destination. Bien que ce type soit similaire à l’ETL, il présente quelques différences essentielles telles que :
- La consolidation des données se concentre davantage sur des concepts tels que le nettoyage et la normalisation des données et la résolution des entités, tandis que l’ETL se concentre sur la transformation des données.
- Alors que l’ETL est une meilleure option pour le big data, la consolidation des données est un type plus approprié pour relier les enregistrements et identifier de manière unique les principaux actifs de données, tels que le client, le produit et l’emplacement.
- Les entrepôts de données aident principalement à l’analyse des données et à la BI, tandis que la consolidation des données est également utile pour améliorer les opérations commerciales, comme l’utilisation du dossier consolidé d’un client pour le contacter ou créer des factures, etc.
4. La virtualisation des données
Comme son nom l’indique, ce type d’intégration de données ne crée pas réellement une copie des données ou ne les déplace pas vers une nouvelle base de données avec un modèle de données amélioré. Il introduit plutôt une couche virtuelle qui se connecte à toutes les sources de données et offre un accès uniforme comme une application frontale.
Comme elle ne dispose pas de son propre modèle de données, la couche virtuelle a pour but d’accepter les demandes entrantes, de créer des résultats en interrogeant les informations requises dans les bases de données connectées et de présenter une vue unifiée. La virtualisation des données réduit le coût de l’espace de stockage et la complexité de l’intégration, puisque les données semblent intégrées mais résident séparément dans les systèmes sources.
5. Fédération de données
La fédération de données est similaire à la virtualisation des données et est souvent considérée comme son sous-type. Encore une fois, dans la fédération de données, les données ne sont pas copiées ou déplacées vers une nouvelle base de données, mais un nouveau modèle de données est conçu qui représente une vue intégrée des systèmes sources.
Il fournit une interface frontale d’interrogation et, lorsque des données sont demandées, il les extrait des sources connectées et les transforme en modèle de données amélioré avant de présenter les résultats. La fédération de données est utile lorsque les modèles de données sous-jacents des systèmes sources sont trop différents et doivent être mis en correspondance avec un modèle plus récent afin d’utiliser les informations plus efficacement.
Processus d’intégration des données
Quel que soit le type d’intégration de données, le flux du processus d’intégration de données est similaire pour tous, car l’objectif est de combiner et de rassembler les données. Dans cette section, nous examinons un cadre général d’intégration de données d’entreprise que vous pouvez utiliser lors de la mise en œuvre de toute technique d’intégration de données.
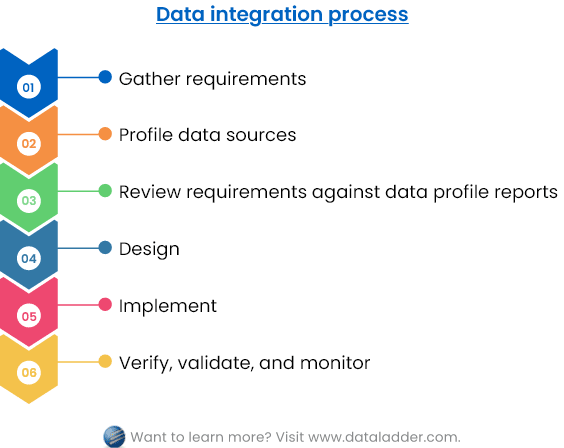
1. Collecte des besoins
La première étape de tout processus d’intégration de données consiste à recueillir et à évaluer les exigences commerciales et techniques. Cela vous aidera à planifier, concevoir et mettre en œuvre un cadre qui produira les résultats escomptés. Voici un certain nombre de domaines à couvrir lors de la collecte des exigences :
- Avez-vous besoin d’intégrer des données en temps réel ou par lots à des moments programmés ?
- Devez-vous créer une copie des données pour ensuite les intégrer, ou mettre en place une couche virtuelle qui intègre les données à la volée sans répliquer les bases de données ?
- Les données intégrées doivent-elles suivre un nouveau modèle de données amélioré ?
- Quelles sources doivent être intégrées ?
- Quelle sera la destination des données intégrées ?
- Quels départements fonctionnels de l’organisation ont besoin d’accéder aux informations intégrées ?
2. Profilage des données
Une autre étape initiale du processus d’intégration des données consiste à générer des rapports de profilage ou d’évaluation des données qui doivent être intégrées. Cela vous aidera à comprendre l’état actuel des données et à découvrir des détails cachés sur leur structure et leur contenu. Un rapport sur le profilage des données identifie les valeurs vides, les types de données des champs, les modèles récurrents et d’autres statistiques descriptives qui mettent en évidence les possibilités de nettoyage et de transformation des données.
3. Examen des profils par rapport aux exigences
Avec les exigences d’intégration et les rapports d’évaluation en main, il est maintenant temps d’identifier l’écart entre les deux. De nombreuses fonctionnalités demandées lors de la phase de définition des besoins ne sont pas valables ou ne correspondent pas aux rapports profilés des données existantes. Mais la comparaison entre les deux vous aidera à planifier une conception de l’intégration qui répond à autant d’exigences que possible.
4. Conception
Il s’agit de la phase de planification du processus au cours de laquelle vous devez concevoir certains concepts clés sur l’intégration des données, tels que :
- La conception architecturale qui montre comment les données vont circuler entre les systèmes,
- Les critères de déclenchement qui décident quand l’intégration aura lieu ou ce qui la déclenchera,
- Le nouveau modèle de données amélioré et les mappages de colonnes qui définissent le processus de consolidation,
- Les règles de nettoyage, de normalisation, de mise en correspondance et d’assurance qualité des données qui doivent être configurées pour une intégration sans erreur, et
- La technologie qui sera utilisée pour mettre en œuvre, vérifier, surveiller et itérer le processus d’intégration.
5. Mettre en œuvre
Une fois le processus d’intégration conçu, il est temps de l’exécuter. L’exécution peut se faire de manière incrémentielle – en intégrant de faibles volumes de données provenant de sources moins conflictuelles, puis en augmentant itérativement les volumes et en ajoutant d’autres sources. Cela peut être utile pour détecter les erreurs initiales qui peuvent survenir. Une fois l’intégration des données existantes terminée, vous pouvez maintenant vous concentrer sur l’intégration des nouveaux flux de données entrants.
6. Vérifier, valider et contrôler
Au cours de la phase de vérification, vous devez tester l’exactitude et l’efficacité du processus d’intégration des données. Le profilage de la source de destination peut être un bon moyen de détecter les erreurs et de valider l’intégration. Un certain nombre de domaines doivent être testés avant que l’installation d’intégration ne puisse être confiée à des activités futures, comme par exemple :
- La perte de données est minime ou nulle,
- La qualité des données ne s’est pas détériorée après l’intégration,
- Le processus d’intégration fonctionne systématiquement comme prévu,
- La signification des données n’a pas changé pendant l’intégration,
- Les mesures mentionnées ci-dessus sont toujours valables après un certain temps.
Intégration et qualité des données : Trop intégrées pour être différenciées
Avant de poursuivre, discutons d’un concept important lié à l’intégration des données qui sème souvent la confusion : la relation entre l’intégration des données et la qualité des données.
D’un point de vue global, l’intégration des données et la qualité des données ont le même objectif : rendre l’utilisation des données plus facile et efficace. Pour atteindre cet objectif, on ne peut mentionner l’intégration des données sans la qualité des données, et vice versa. Cela peut devenir confus si vous essayez de comprendre où finit l’un et où commence l’autre. La vérité est que ces deux concepts sont trop intégrés pour être différenciés et doivent être traités de manière transparente.
Les efforts d’intégration de données qui ne tiennent pas compte de la qualité des données sont voués à l’échec. La gestion de la qualité des données est un catalyseur de votre processus d’intégration de données car elle améliore et accélère la consolidation des données.
Une autre distinction entre les deux est que la qualité des données n’est pas une initiative – mais une habitude ou un exercice qui doit être constamment contrôlé. Bien que dans le cas des entrepôts de données, l’intégration des données puisse se faire à des moments précis de la semaine ou du mois, vous ne pouvez pas oublier la qualité des données même pendant cette attente. La qualité des données est donc primordiale pour obtenir des résultats d’intégration de données réussis et utilisables.
Outils et solutions d’intégration de données
Compte tenu des grands volumes de données que les organisations stockent et intègrent, les efforts manuels sont hors de question pour la plupart des initiatives d’intégration. L’utilisation de la technologie pour intégrer et consolider les données résidant dans des sources distinctes peut s’avérer plus efficace, efficiente et productive. Voyons maintenant quelles sont les caractéristiques communes que vous pouvez rechercher dans une plateforme d’intégration de données :
- La possibilité d’extraire des données d’une grande variété de sources, telles que des bases de données SQL ou Oracle, des feuilles de calcul et des applications tierces.
- La possibilité de profiler des ensembles de données et de générer un rapport complet sur leur état en termes d’exhaustivité, de reconnaissance des formes, de types et de formats de données, etc.
- La possibilité d’éliminer les ambiguïtés, telles que les valeurs nulles ou les valeurs résiduelles, de supprimer le bruit, de corriger les fautes d’orthographe, de remplacer les abréviations, de transformer le type et le modèle de données, etc.
- La possibilité de mapper des attributs appartenant à des sources de données distinctes pour mettre en évidence le flux d’intégration.
- La capacité d’exécuter des algorithmes de comparaison de données et d’identifier les enregistrements appartenant à la même entité.
- La possibilité d’écraser les valeurs lorsque cela est nécessaire et de fusionner les enregistrements entre les sources afin d’obtenir le disque d’or.
- La possibilité d’exécuter l’intégration des données à des moments planifiés ou de les intégrer en temps réel via des appels API ou d’autres mécanismes similaires.
- La possibilité de charger les données intégrées dans n’importe quelle base de données ciblée.
Unifier l’intégration, le nettoyage et le rapprochement des données
L’intégration de grandes quantités de données peut s’avérer être une initiative écrasante, surtout si vous optez pour une configuration ETL ou de virtualisation des données. Un environnement d’intégration de données de base qui rassemble les données tout en minimisant les défauts intolérables de qualité des données peut être un bon point de départ pour la plupart des entreprises. En donnant la priorité à l’aspect unique et le plus important de l’intégration des données pour la consolidation des données, vous pouvez commencer à un niveau bas et l’améliorer progressivement si nécessaire.
Vous pouvez commencer par utiliser une solution d’intégration de données unifiée qui offre une variété de connecteurs communs ainsi que des fonctions intégrées pour le profilage, le nettoyage, la normalisation, la mise en correspondance et la fusion des données. En outre, une fonction de planification qui intègre les données par lots à des moments configurés peut donner le coup d’envoi de votre initiative en quelques jours.
DataMatch Enterprise est l’un de ces outils de consolidation de données qui peut vous aider à intégrer vos données résidant dans des sources distinctes. Téléchargez une version d’évaluation dès aujourd’hui ou réservez une démonstration avec nos experts pour voir comment nous pouvons vous aider à mener à bien votre initiative d’intégration de données.



