































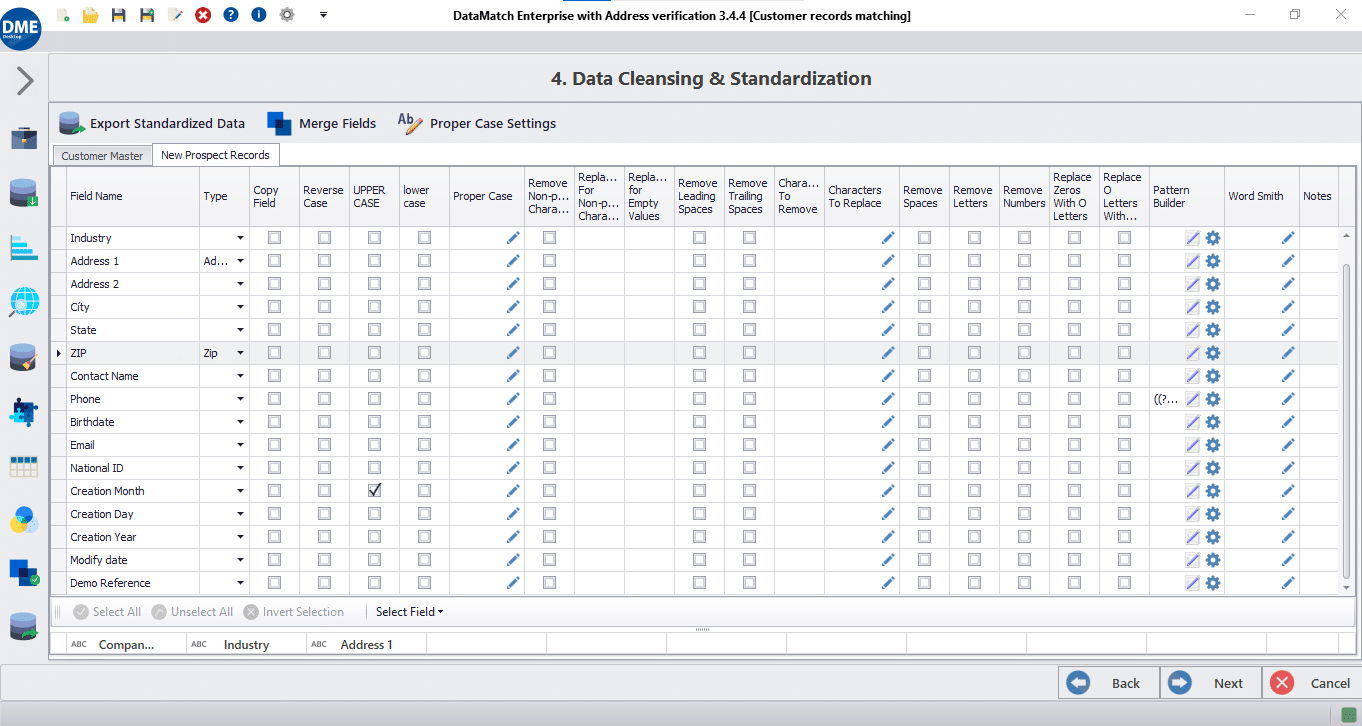








Data profiling tools identify the pattern a column follows and calculate the number of valid and invalid values against the identified pattern. You can use DME’s library of commonly used patterns or create your own using our simple drag and drop pattern builder.

Data analysts

Business users

IT Professionals

Novice users


Merging Data from Multiple Sources – Challenges and Solutions

SAP Is Acquiring Reltio. Here Is What Reltio Customers Need to Know.
Last Updated on April 2, 2026 On March 27, 2026, SAP said it would acquire Reltio, a leading enterprise master data management platform. The deal should close
EMPI vs Entity Resolution: What Healthcare IT Teams Need to Know
Last Updated on March 3, 2026 The average healthcare organization carries 8% to 12% duplicate patient records, and in large health systems, that number often rises to 15% to
SAP Is Acquiring Reltio. Here Is What Reltio Customers Need to Know.
Last Updated on April 2, 2026 On March 27, 2026, SAP said it would acquire Reltio, a leading enterprise master data management platform. The deal should close
EMPI vs Entity Resolution: What Healthcare IT Teams Need to Know
Last Updated on March 3, 2026 The average healthcare organization carries 8% to 12% duplicate patient records, and in large health systems, that number often rises to 15% to
Dedupe Software Tools for Multi-Source Data Integration
Last Updated on February 27, 2026 Dedupe software identifies and removes duplicate records from databases, CRMs, and other data systems so organizations maintain a single,
