





























Last Updated on mai 19, 2022
Lors d’une enquête menée auprès de 1900 équipes chargées des données, plus de 60 % ont cité le nombre trop élevé de sources de données et l’incohérence des données comme étant le principal problème de qualité des données qu’elles rencontrent. Mais lorsqu’ils sont confrontés à la tâche d’améliorer la qualité des données, les responsables des données se trouvent souvent dans une situation difficile, car ils doivent prendre des décisions cruciales. L’une des décisions les plus importantes à prendre est la suivante : à quel moment du cycle de vie des données doit-on tester et corriger la qualité des données ?
Pour répondre à cette question, quelques aspects doivent être pris en compte. Étant donné que de nombreuses entreprises produisent régulièrement d’énormes quantités de données et les utilisent de manière constante dans toute l’organisation, une approche réactive – où les données sont nettoyées après leur stockage – n’est peut-être pas le meilleur choix, car elle a un impact sur la fiabilité et la disponibilité des données. Le déploiement d’un pare-feu central pour la qualité des données – où les données sont testées et traitées avant d’être stockées dans la base de données – pourrait être une meilleure option dans de tels cas.
Pour en savoir plus sur les différences entre ces deux approches, consultez notre dernier blog : Traitement par lots versus validation de la qualité des données en temps réel.
Dans la plupart des approches réactives, les responsables des données ou d’autres membres de l’équipe chargée de la qualité des données utilisent une interface logicielle pour tester et corriger la qualité des données. Mais dans une approche proactive, cette tâche est généralement gérée par une API. Dans ce blog, nous examinerons les différents aspects à prendre en compte lors du déploiement d’un pare-feu de qualité des données utilisant ces API. Commençons.
Qu’est-ce qu’une API de qualité des données ?
En termes simples, une API (interface de programmation d’applications) est un intermédiaire logiciel qui permet aux applications de communiquer entre elles. Une API réside entre deux applications logicielles et gère les demandes/réponses transmises. Habituellement, lorsque vous souhaitez intégrer ou connecter deux systèmes, vous le faites à l’aide d’une API.
De même, une API de qualité des données signifie :
Un intermédiaire logiciel qui sert les demandes/réponses pour diverses fonctions de qualité des données.
Mise en œuvre architecturale d’une API de qualité des données
Une API de qualité des données est souvent désignée par différents noms. Par exemple, pare-feu de qualité des données, validation de la qualité des données en temps réel, moteur central de qualité des données, etc. Ces noms sont donnés car l’API fonctionne entre l’application qui saisit les données et la base de données qui les stocke.
Les API de qualité des données (comme toute autre API) reposent sur une architecture pilotée par les événements. Ils sont déclenchés lorsqu’un événement se produit. Ainsi, chaque fois que de nouvelles données arrivent par une application connectée ou que des données existantes sont mises à jour, elles passent d’abord par l’API (où la qualité des données est vérifiée), puis elles sont dirigées vers la base de données source. L’API fait ainsi office de passerelle entre une application de capture des données et une source de stockage des données, ce qui garantit qu’aucune erreur de qualité des données n’est transférée de la première extrémité à la seconde.
Exemple de validation de la qualité des données en temps réel pour les données clients
Lorsque vous déployez un pare-feu central pour la qualité des données, la qualité des données entrantes est vérifiée en quasi temps réel. Par exemple, lorsqu’une modification est apportée à un enregistrement client ou lorsqu’un nouvel enregistrement client est créé dans une application connectée, la mise à jour est d’abord envoyée au moteur central de qualité des données. Ici, la modification est vérifiée par rapport à la définition de la qualité des données configurée, en s’assurant par exemple que les champs obligatoires ne sont pas vides, que les valeurs respectent le format et le modèle standard, qu’un nouvel enregistrement client ne peut pas correspondre à un enregistrement client existant, etc.
Si des erreurs de qualité de données sont trouvées, une liste de règles de transformation est exécutée pour nettoyer les données. Dans certains cas, vous pouvez avoir besoin d’un responsable de la qualité des données pour intervenir et prendre des décisions lorsque les valeurs des données sont ambiguës et ne peuvent pas être bien traitées par les algorithmes configurés. Par exemple, il se peut qu’il y ait 60 % de chances qu’un nouvel enregistrement client soit un doublon, et quelqu’un devra vérifier manuellement et résoudre le problème. Une fois cette opération effectuée, l’enregistrement de données nettoyé, apparié et vérifié est ensuite envoyé à une source de destination, qui peut être un ensemble de données de base, un entrepôt de données, un système de veille économique, etc.
Un exemple d’une telle architecture est représenté schématiquement ci-dessous :
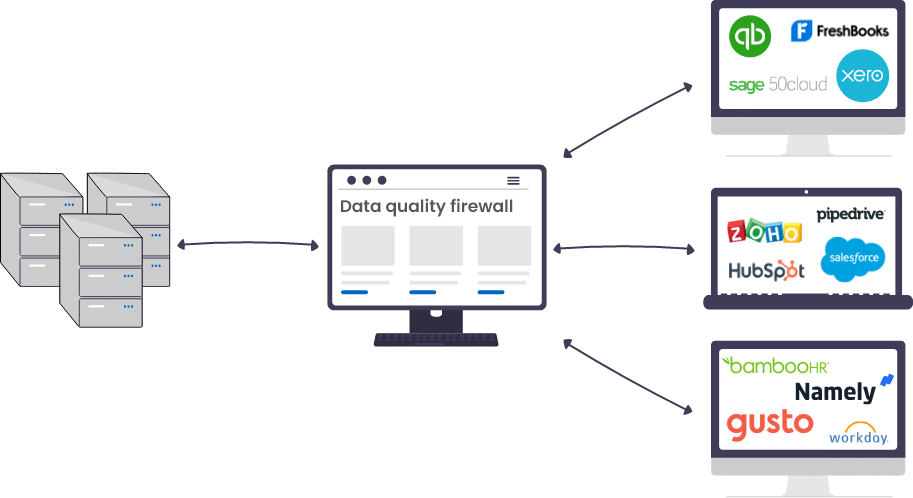
Fonctions d’une API de qualité des données
Une bonne API de qualité des données est capable d’exécuter différents types de fonctions de qualité des données sur les données entrantes. En fonction des processus inclus dans votre cadre de qualité des données, vous pouvez vous abonner aux fonctions requises via l’API. Mais comme la plupart des organisations ne peuvent se permettre de laisser passer des problèmes récurrents ou nouveaux de qualité des données, elles souscrivent le plus souvent à un maximum de techniques de validation et de correction de la qualité des données offertes par l’API.
Les fonctions les plus courantes exposées par une API de qualité des données sont les suivantes :
1. Se connecter aux sources de données
Il s’agit de la fonctionnalité principale et la plus avantageuse qu’offre une API de qualité des données. Les organisations utilisent de multiples applications générant des données, par exemple, des outils de suivi de site web, des outils d’automatisation du marketing, des CRM, etc. C’est pourquoi une API de qualité des données doit être capable de se connecter et de dialoguer avec ces différentes applications, ainsi qu’avec la base de données de destination où aboutissent généralement les données entrantes.
2. Effectuer des contrôles de qualité des données
Chaque fois qu’un événement se produit dans une application connectée (un nouvel enregistrement est créé ou un enregistrement existant est mis à jour), l’API peut évaluer et profiler les données entrantes pour détecter les erreurs de qualité des données. Pour ce faire, il exécute des algorithmes statistiques qui évaluent les données entrantes et vérifient si elles sont conformes à la définition de la qualité des données. Ces contrôles consistent notamment à s’assurer que :
- Les champs obligatoires ne sont pas laissés vides,
- Les champs suivent le type de données, le modèle et le format corrects, et se situent dans la plage valide,
- Un nouvel enregistrement est unique et n’est pas un doublon d’un enregistrement existant,
- Les nouvelles données sont validées par rapport à des règles commerciales personnalisées.
3. Corriger les problèmes de qualité des données
Une API de qualité des données offre un certain nombre de fonctions permettant de corriger les erreurs et les problèmes découverts lors du profilage des données. Ces fonctions incluent (mais ne sont pas limitées à) :
- Analyse des champs agrégés en sous-composants pour créer des valeurs de champ plus significatives,
- Transformer les types de données, les modèles et les formats lorsque cela est nécessaire,
- Suppression des espaces, caractères ou mots inutiles,
- Convertir les abréviations en mots propres,
- Écraser ou fusionner un nouvel enregistrement avec le doublon (dans le cas où un enregistrement pour la même entité existe déjà).
4. Déclencher des alertes pour une révision manuelle
Parfois, une API de qualité des données est incapable de résoudre certains problèmes de qualité des données qui sont complexes par nature. Dans de tels cas, des alertes sont transmises aux parties prenantes appropriées (gestionnaires ou analystes de données) afin que les erreurs puissent être examinées manuellement et que l’une des actions suggérées soit prise. Par exemple, un nouvel enregistrement est suspecté d’être un doublon avec un rapport de vraisemblance de 65%. Ces situations ambiguës nécessitent une intervention humaine pour résoudre le problème et prendre la bonne décision.
5. Déplacer les données vers la source de destination
Une fois que les données ont été validées et qu’elles respectent la norme de qualité requise, la dernière fonction de l’API consiste à les transférer vers la source de destination. Parfois, il s’agit simplement d’une base de données unique, alors que dans d’autres cas, il peut y avoir plusieurs emplacements de sortie, tels qu’un système de veille stratégique, un entrepôt de données ou d’autres applications tierces, etc.
Avantages d’une API de qualité des données
Voici quelques avantages du déploiement d’un pare-feu central pour la qualité des données :
1. Maximiser la fiabilité et la disponibilité des données
Selon le rapport Rethink Data Report 2020 de Seagate, seuls 32 % des données d’entreprise sont exploitées, tandis que les 68 % restants sont perdus en raison de l’indisponibilité et du manque de fiabilité des données.
L’un des principaux avantages de la validation de la qualité des données en temps réel est qu’elle garantit un état fiable des données à tout moment en validant et en corrigeant la qualité des données instantanément après chaque mise à jour. Étant donné qu’une API de qualité des données traite, nettoie et normalise les données dès qu’elles entrent dans le système, elles ont plus de chances d’être disponibles lorsqu’un consommateur interroge les données pour effectuer des tâches de routine.
2. Améliorer l’efficacité commerciale et opérationnelle
Une étude récente montre que 24 % des équipes chargées des données utilisent des outils pour détecter les problèmes de qualité des données, mais ceux-ci ne sont généralement pas résolus.
La plupart des outils de qualité des données sont capables de détecter les problèmes et de déclencher des alertes en cas de détérioration de la qualité des données en dessous d’un seuil acceptable. Mais ils laissent de côté un aspect important : l’automatisation de l’exécution des processus de qualité des données (que ce soit en fonction du temps ou de certains événements) et la résolution automatique des problèmes. L’absence de cette stratégie oblige à une intervention humaine – ce qui signifie que quelqu’un doit déclencher, superviser et terminer les processus de qualité des données dans l’outil pour résoudre ces problèmes.
Il s’agit d’une surcharge importante qu’un pare-feu de qualité des données résout facilement. Les organisations souhaitent investir dans la création d’un moteur central de qualité des données capable d’exécuter des techniques avancées de qualité des données avec une intervention humaine minimale. Cela a un impact positif sur l’efficacité opérationnelle de l’entreprise et la productivité des équipes.
3. Construire des solutions personnalisées
De nos jours, la définition des données de qualité est contrôlée par son organisation et dépend de règles commerciales spécialisées. Les techniques de validation des données mises en œuvre dans les formulaires de saisie ou exécutées par un script python vieux d’un an ne suffisent pas. Les entreprises cherchent désormais à créer leur propre moteur de qualité des données, conçu pour répondre à leurs besoins spécifiques. C’est là qu’une API de qualité des données offre d’énormes avantages, que vous souhaitiez concevoir votre propre cadre de qualité des données, votre architecture de gestion des données ou des solutions de données personnalisées.
4. Obtenir un meilleur contrôle de la validation de la qualité des données
La meilleure partie d’une API est la capacité de personnalisation ou d’adaptation qu’elle offre. Cela peut vous permettre de mieux contrôler le fonctionnement de vos processus et les résultats qu’ils produisent. Par exemple, vous pouvez définir des règles de gestion personnalisées pour la validation de la qualité des données, ainsi que configurer des seuils et des variables adaptés aux ensembles de données de votre organisation.
Un autre exemple est l’intégration au système d’un portail personnalisé de suivi des problèmes qui envoie des alertes aux responsables des données lorsqu’un problème nécessite une attention immédiate. Les responsables des données peuvent utiliser le portail pour effectuer un examen manuel et annuler les décisions si nécessaire.
5. Mettre en œuvre des politiques efficaces de gouvernance des données
Un autre avantage du déploiement d’un pare-feu central pour la qualité des données est de garantir une mise en œuvre efficace des politiques de gouvernance des données. Le terme de gouvernance des données fait généralement référence à un ensemble de rôles, de politiques, de flux de travail, de normes et de mesures qui garantissent une utilisation et une sécurité efficaces des informations et permettent à une entreprise d’atteindre ses objectifs commerciaux.
La mise en œuvre personnalisée d’une solution de qualité des données à l’aide d’une API peut aider à créer les rôles et les autorisations nécessaires pour les données, à concevoir des flux de travail pour vérifier les mises à jour des informations, à collaborer pour fusionner plusieurs ressources de données, à suivre qui a mis à jour les informations et quand, etc.
6. Sources de données pour la recherche intelligente
Étant donné qu’un pare-feu de qualité des données se connecte à toutes les principales sources de données d’une organisation, cette architecture présente des avantages cachés, et l’un d’eux est la recherche intelligente de données dans toutes les sources. C’est un avantage lorsque les entreprises veulent interroger intelligemment les données d’une ou plusieurs bases de données sans utiliser de scripts SQL ou de langages de programmation avancés. Un pare-feu de qualité des données peut y contribuer car il abrite des algorithmes complexes et avancés de mise en correspondance des données.
Par exemple, lorsque vous recherchez dans des sources connectées des enregistrements dont le prénom est Elizabeth, l’API exécute des règles de gestion logiques pour interroger et faire correspondre les données – y compris des techniques de correspondance de données floues, phonétiques et spécifiques à un domaine. Cela offre des résultats intelligents en temps réel où les enregistrements ayant une variation possible du mot Elizabeth comme prénom sont également recherchés et affichés, tels que Elisabeth, Alizabeth, Lisa, Beth, etc.
7. Réduire les tracas de l’importation/importation/exportation
Un autre avantage du déploiement d’une API de qualité des données est qu’il réduit les tracas de l’exportation, de l’importation et de la réimportation des données. Cela doit être fait en utilisant un outil autonome de qualité des données pour nettoyer, apparier et vérifier les ensembles de données. Grâce à une API, vous pouvez effectuer toutes les opérations de nettoyage, de rapprochement et de vérification des adresses sans jamais quitter votre système source. Il permet à votre outil de qualité des données de communiquer directement avec plusieurs sources de données pour trouver tous les enregistrements associés. Il peut également apporter automatiquement des modifications aux données, ce qui vous fait gagner du temps et de l’argent, et réduit les risques d’erreurs.
8. Ajout automatique aux entrepôts de données
Les organisations stockent et conservent des tonnes de données historiques sur les clients, les produits et les fournisseurs dans des entrepôts de données. Des millions de ces enregistrements sont générés quotidiennement ou hebdomadairement. Mais avant que de nouveaux enregistrements puissent être déplacés vers l’entrepôt de données de base, il doit être testé pour les normes de qualité des données appropriées, et dans le cas de doublons, il doit être mis en correspondance pour s’assurer que l’enregistrement à venir enrichit l’ancien et n’est pas créé à nouveau comme un nouveau record.
C’est là qu’une API de qualité des données est particulièrement performante : elle traite de grandes quantités de données en arrière-plan, quasiment en temps réel, et extrait l’identifiant unique d’un enregistrement existant, effectue une mise en correspondance des données pour identifier les correspondances exactes ou floues et ajoute de nouveaux attributs de données à l’enregistrement existant.
Conclusion
La mise en œuvre de mesures de qualité des données cohérentes, automatisées et reproductibles peut aider votre organisation à atteindre et à maintenir la qualité des données dans tous les ensembles de données en temps réel.
Data Ladder a servi dessolutions de qualité des données à ses clients depuis plus d’une décennie maintenant. DataMatch Enterprise est l’un de ses principaux produits de qualité des données, disponible sous la forme d’une application autonome ou d’une solution intégrée. API – qui vous permet d’utiliser n’importe quelle fonction de gestion de la qualité des données dans votre application personnalisée ou existante, et de la configurer en temps réel. connexion à la source de données, leprofilage, nettoyage, correspondant, déduplication, et purge de la fusion.
Vous pouvez télécharger l’essai gratuit dès aujourd’hui ou programmer une session personnalisée avec nos experts pour comprendre comment les capacités API de DME peuvent vous aider à créer votre propre solution personnalisée et à tirer le meilleur parti de vos données.



