































Last Updated on April 16, 2026
Poor data quality can have devastating risks on your business. Most organizational workers realize the impact of of poor data quality, but it is hard for them to build a case for it on paper. Whether they want to justify the investment in data quality improvement plans or convince their line managers to take action. This is why it becomes imperative to relate data quality issues to potential business risks and associated costs, so that you can get the attention of necessary stakeholders in time and implement possible fixes.
In this blog, we will look at how various data quality issues can introduce serious risks to your business and what possible measures you can take to overcome them.
Designing the data flaw – business risk matrix
David Loshin (in his book The practitioner’s guide to data quality improvement) introduces a very useful template for relating data flaws to business impacts and resulting costs. I have summarized the template in the table below:
| Problem | Issue | Business risk | Quantifier | Cost (yearly) |
| This is the data quality problem that resides in your dataset. | These are the various issues that can arise due to the data problem. | This is the impact the issue can have on the business. | This quantifies the impact in terms of a business measure. | This provides a periodic estimated cost incurred due to the business impact. |
| Example | ||||
| Misspelled customer name and contact information | Duplicate records created for the same customer | Customer service: Increased number of inbound calls | Increased staff time | $30,000.00 worth more staff time required |
| Customer service: Decreased customer satisfaction | Order reduction, lost customers | ~500 less orders this year (as compared to estimated) | ||
| Accounts: Impact on cash flow | Increase in cash flow volatility | Cannot trust estimated cash flow about 20% of the time | ||
| Accounts: Increased audit demand | Increased staff time | $20,000.00 worth more staff time required |
This template precisely summarizes the kind of impact a data quality issue (something as small as a misspelled customer name) can have on your business. There are a few things to note about this template:
- A data quality Problem can give rise to multiple Issues. For example, a misspelled customer name or contact information can also lead to an incorrect customer in your database and losing the contact of an authentic customer.
- A single Issue can have multiple Impacts on various business verticals. In the table above, we saw how an issue had two impacts on Customer Service and two impacts on the Accounts department. The same issue can have more impact on these departments, or possibly more impact on other verticals, such as Sales, Marketing, Product, etc.
- The Quantifier is necessary to track down and there can be multiple quantifiers for a single Impact.
- The Cost is estimated and can be measured at any periodic time, for example, monthly, quarterly, yearly, etc.
The template mentioned above sets the stage for relating all kinds of data quality issues to estimated business risks. But just to help you fill up the template for your specific business case, I am listing the following aspects in this blog:
- The different types of data quality issues present in the main data assets of an organization, and
- The most common business risks incurred due to these data quality issues.
Let’s get started.

5 Common data quality issues, their causes, and how to overcome them
Let’s take a look at the most common quality issues found in an organization’s datasets.
- Incomplete Data: Missing values or records.
- Inaccurate Data: Incorrect or erroneous data.
- Duplicate Data: Multiple entries for the same entity.
- Inconsistent Data: Variations in data format or representation.
- Outdated Data: Data that is no longer current.
All of the above data quality issues occur due to at least one of the following reasons:
Lack of Data Governance and Standardization
A lack of data governance leads to inconsistencies and errors in managing data, with standardization being a key element of this governance.
- Data Governance: The framework and processes organizations use to manage, protect, and ensure the quality, consistency, and security of its data assets.
- Data Standardization: The practice of implementing uniform data formats, definitions, and protocols across an organization to ensure consistency and compatibility in data management.
Without proper governance and standardization, data formats, definitions, and handling processes vary across departments, and that results in fragmented and unreliable data. To make sure that doesn’t happen to your organization, make sure you:
- Develop Standardized Data Formats: Create and enforce uniform data formats and definitions that apply to all departments and systems. For example, establish a consistent format for dates, currency, and customer IDs across the organization.
- Implement Data Quality Monitoring: Regularly audit and monitor data to ensure compliance with governance policies and standards. Use tools like Data Ladder for data profiling, cleansing, matching, and deduplication.
- Provide Training and Support: Educate staff on the importance of data governance and how to adhere to standardized practices to prevent and resolve bad data quality issues. Start with courses like data governance fundamentals and best practices.
- Use Data Governance Tools: Invest in tools that help automate and enforce governance and standardization across the organization. Use tools like Atlan and Fivetran.
Creating a data governance strategy and implementing standardization also helps you minimize human error and data entry issues. For example, with strict data standards in place, all employees will follow the same formats and protocols for data entry. This will reduce the likelihood of errors due to varying practices or misunderstandings.
Data governance also helps solve issues created by outdated processes and legacy systems, since it provides a structured framework for updating and integrating these systems into modern workflows. By enforcing consistent data standards and practices, data governance ensures that even older systems align with current business needs. This, in turn, reduces discrepancies and improves overall data quality and interoperability across the organization.

External Data Sources
Organizations rely on internal and external data to perform analyses, train AI models, and a number of other tasks. External data sources include data obtained from third-party vendors, public databases, social media, and other outside entities.
While external data can enrich internal datasets and provide valuable insights, it also introduces risks related to accuracy, consistency, and relevance. Without rigorous validation and integration processes, external data can lead to discrepancies, outdated information, and a lack of alignment with internal standards.
To mitigate these risks, implement stringent data governance practices that include thorough vetting, cleansing, and standardization of external data before it is integrated into internal systems. This ensures that external data supports, rather than undermines, the quality and reliability of the organization’s overall data ecosystem. Use tools like Data Ladder to profile third party data, cleanse it, and match it with your database to avoid duplication, inaccuracies, and inconsistencies.

Complex Data Infrastructure
In larger organizations, data is often spread across multiple systems, databases, and departments, each with its own processes and formats. This fragmentation creates significant challenges for maintaining data quality, as it leads to inconsistencies, duplication, and difficulties in data integration.
Managing such a complex environment requires a comprehensive data governance strategy that ensures consistent standards and processes are applied across all data sources. By doing so, organizations can unify their data, reduce errors, and improve overall data reliability and accessibility.
Additionally, tools like Data Ladder can play a role in managing complex data infrastructures by offering powerful data profiling, cleansing, and matching capabilities that help to streamline and unify data from disparate sources.
Integration and Migration Issues
Integration and migration issues occur when data is transferred between systems, often during upgrades, mergers, or the adoption of new technologies. These processes are complex and can introduce errors, inconsistencies, and data loss if not managed carefully.
Misalignment between old and new systems, incompatible data formats, and incomplete data transfer are common challenges. To mitigate these risks, it’s essential to have a robust data governance framework that includes detailed planning, testing, and validation steps to ensure that data integrity is maintained throughout the process.

System Errors
System errors, such as software glitches, hardware failures, or network interruptions, can severely impact data quality. These errors can lead to corrupted files, lost data, or incomplete transactions, all of which compromise the reliability and accuracy of an organization’s data.
Regular maintenance, monitoring, and updating of systems are crucial to prevent such errors. Additionally, implementing data backup and recovery solutions can help organizations minimize data loss and quickly restore operations in the event of a system failure. Data governance also plays a key role in ensuring that procedures are in place to detect, address, and prevent system-related data quality issues.
The definitive buyer’s guide to data quality tools
Download this guide to find out which factors you should consider while choosing a data quality solution for your specific business use case.
DownloadBusiness risks associated with poor data quality
To estimate the impact of poor data quality on a business, you need to identify the role data plays in various business processes. This will help you highlight which processes are bound to mess up and cause delays if the data had any of the issues mentioned above. Below, I have listed the most common business risks associated with poor data quality.

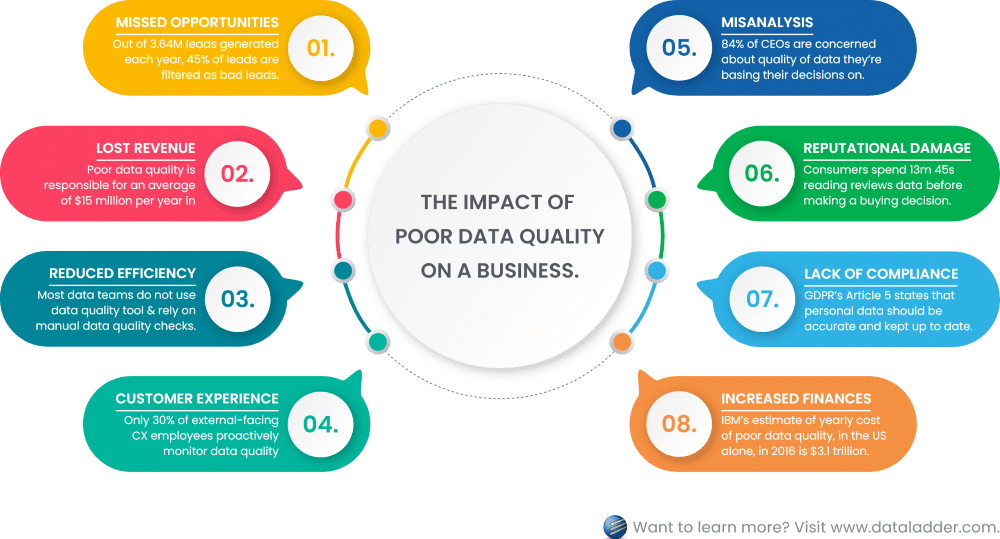
1. Missed opportunities
Out of 3.64M leads generated each year, 45% of leads are filtered as bad leads due to duplicated data, invalid formatting, failed email validation, and missing fields. – Source
A business is prone to miss opportunities on multiple fronts if they have poor data quality across disparate datasets. For example, with poor lead data, you can miss an opportunity to identify potential prospects. Similarly, poor product information can strain your ability to effectively strategize your product development according to market needs. Competitors in your landscape will definitely take the lead in the market if they have more reliable and accurate datasets.
2. Lost revenue
Organizations believe poor data quality to be responsible for an average of $15 million per year in losses. – Source
This is definitely one of the biggest risks that your business can experience due to poor data quality. Incomplete or incorrect data (either it is customer contact information, product information, or ambiguity in financial dataset) can cause you to lose potential clients and incur losses in revenue as a result. If these mistakes are not connected to poor data quality management, you will have a hard time understanding why your team is unable to reach their annual sales or revenue targets.

3. Reduced operational efficiency and productivity
Most data teams in 2021 said that they do not use any data quality software and rely on manual data quality checks. – Source
When an organization’s workforce manually corrects data quality issues before using the data, it can put a strain on their efficiency and productivity rates. Many data analysts and data scientists feel that they spend more time preparing and cleaning data – as compared to performing analysis and forecasting reliable predictions about the business’s future. For this reason, your business needs an end-to-end system that utilizes technology to automate data quality validation and implement data quality processes in time. This can transform your data into making it usable at every stage of its lifecycle – without putting in any extra effort in runtime.
4. Customer dissatisfaction
Out of 37% of respondents working on customer experience for external-facing processes, only 30% proactively monitor data quality impacts. – Source
In this era, customers seek personalization. The only way to convince them to buy from you and not a competitor is to offer them an experience that is special to them. Make them feel they are seen, heard, and understood. To achieve this, businesses use a ton of customer-generated data to understand their behavior and preferences. If this data has serious defects, you will obviously end up inferring wrong details about your customers or potential buyers. This can lead to reduced customer satisfaction and brand loyalty.
How to build a unified, 360 customer view
Download this whitepaper to learn why it’s important to consolidate your customer data and how you can get a 360 view of your customers.
Download5. Misanalysis
84% of CEOs are concerned about the quality of the data they’re basing their decisions on. – Source
There are two ways to predict future market, demand, and need. One is to follow your instinct. The second is to look at past data to identify patterns and forecast the probable future. It is obvious that the second way is more reliable. But when it comes to business intelligence or market analysis, your insights are going to be as good as the input data. If the data fed to your analysis algorithm has multiple data quality issues, the identified patterns are going to be inaccurate – leading you to build an incorrect perception about the market’s future.
6. Reputational damage
The average consumer spends 13 minutes and 45 seconds reading reviews before making a buying decision. – Source
Poor product information is one of the biggest reasons that customers return bought products. The product was not how it was marketed on the website. But in some cases, poor data quality can cost you more than just returned products. In March 2017, Rescue 116 crashed into a 282ft obstacle – Blackrock Island off the County Mayo coast. Further investigations revealed that the CHC Ireland helicopter operator did not have “formalized, standardized, controlled, or periodic” system in place. Due to which, the database used by the operator to review flight routes was missing details about Blackrock Island.
It was reported that the crew was not warned of this obstacle in their flight route until they were 13 seconds away from it. The worst part is that a complaint was logged about this inaccuracy of Irish coast guard database 4 years prior to the incident, but no corrective measures were taken. In a world where every action is data-driven, such incidents prove that the cost of poor data quality is highly underestimated.

7. Lack of compliance
GDPR’s Article 5 states that personal data should be accurate and, where necessary, kept up to date. – Source
Data compliance standards (such as GDPR, HIPAA, and CCPA, etc.) are compelling businesses to revisit and revise their data management strategies. Under these data compliance standards, companies are obliged to protect the personal data of their customers and ensure that data owners (the customers themselves) have the right to access, change, or erase their data.
Apart from these rights granted to data owners, the standards also hold companies responsible for following the principles of transparency, purpose limitation, data minimization, accuracy, storage limitation, security, and accountability. It is very difficult to comply with these standards if the underlying data is not accurate, complete, valid, and secure. And a lack of compliance can limit your business operations – especially geographically.
8. Increased financial costs
IBM’s estimate of the yearly cost of poor data quality, in the US alone, in 2016 is $3.1 trillion. – Source
All these business risks mentioned above build up to one thing: it costs you more money than it would have if you had an end-to-end data quality management system in place. Whether you’re paying to hire more staff or constantly updating system processes to ensure data quality, you will not end up with the results you are seeking to achieve. It is best to invest in implementing a single, complete data quality management system that cleans and prepares all different types of data handled at your organization, so that the increasing financial costs can be controlled.
Anti-money laundering screening and data matching
Download this whitepaper to understand the AML compliance dilemma, current system limitations, and how name-matching technology is a critical challenge to AML compliance.
DownloadConclusion
Implementing consistent, automated, and repeatable data quality measures can help your organization to attain and maintain quality of data across all datasets.
Data Ladder has served data quality solutions to its clients for over a decade now. DataMatch Enterprise is one of its leading data quality products – available as a standalone application as well as an integrable API – that enables end-to-end data quality management, including data profiling, cleansing, matching, deduplication, and merge purge.
You can download the free trial today, or schedule a personalized session with our experts to understand how our product can help implement the best practices for attaining and sustaining data quality at an enterprise level.

