































Last Updated on January 26, 2026
From 2013 to 2015, Facebook and Google were tricked into wiring over $100 million to a scammer’s account who impersonated a trusted vendor. The fraud succeeded because the invoices and emails matched those of the actual vendor.
This example shows why correct data matching tuning is critical.
Data matching tuning is the process of adjusting match thresholds, attribute weights, and rule logic to balance accuracy, reduce false positives, and align match behavior with real business risk. False positives in data matching occur when related records are incorrectly merged, often leading to data corruption, compliance risk, and loss of trust.
If records are matched using only a single or a few superficial attributes or without sufficient cross-verification, false positives can slip through.
Proper multi-attribute validation, verification rules, and well-tuned thresholds help ensure that your records match accurately, so errors like this never happen to your business.
Understanding Match Errors That Can Cost Millions
A data matching engine is only as reliable as the rules and thresholds it’s tuned with, or the business process around it.
To improve data matching accuracy, it’s essential to understand the two main types of match errors: false positives and false negatives.
- False positives occur when unrelated entities are incorrectly merged. This can corrupt your data, create compliance or audit risks, and undermine trust in downstream processes.
- False negatives happen when records that should match are left unlinked. These gaps can lead to an incomplete 360o view of customers, blind spots in analytics, and missed business opportunities.
Both false positives and false negatives carry tangible business costs. That’s why data practitioners don’t treat precision (avoiding false positives) and recall (avoiding false negatives) as abstract evaluation metrics, but as operational parameters that must be tuned according to specific objectives and risk profiles.
For effective data matching tuning, you also need to understand where match errors come from. Some arise from threshold decisions (how aggressive or conservative your match scoring rules are) while others stem from issues with the underlying data attributes themselves, like inconsistent, incomplete, or poorly standardized data.
Distinguishing between these error drivers is the first step toward tuning your system effectively and ensuring accurate, actionable matches.
Field Weight Optimization: Assigning Importance Where It Matters
Reducing false positives and false negatives isn’t just about adjusting match thresholds; it also requires understanding which fields carry the most discriminative power.
In enterprise datasets, not all attributes contribute equally to matching decisions. Giving the right weight to each attribute ensures that highly distinctive fields drive your match engine, while less reliable fields don’t introduce unnecessary errors.
Here’s a practical view of how attributes typically influence precision and recall across different business contexts:
Attribute Discriminative Power vs. Typical Business Use Cases
| Attribute | High Precision (e.g., Compliance, Finance) | High Recall (e.g., Marketing, Analytics) | Recommended Weight |
| High | Low | 0.4–0.6 | |
| Phone | Medium | Medium | 0.3–0.5 |
| Name | Low | Medium | 0.2–0.4 |
| Address | Medium | Low | 0.1–0.3 |
How to interpret this table:
- Attributes like email or unique IDs carry high precision; merging records that share them is usually safe.
- Attributes like name or address may vary widely in quality, especially in large or global datasets, so they should carry proportionally less weight.
- Recommended weights are illustrative; the optimal values depend on your datasets, business goals, and tolerance for false positives vs false negatives.
Weighting strategy examples:
- High trust scenarios (e.g., compliance or finance): Increase the weight of email or unique identifiers to prioritize accuracy.
- Coverage-focused scenarios (e. g., marketing or analytics): Reduce the weight of common names to avoid missing potential matches.
- Context-specific adjustments: If your data includes regions with common last names, reduce name weight and rely more on phone or email to differentiate entities.
Proper field weight optimization, combined with threshold tuning, allows your data matching engine to make smarter, more reliable decisions, reducing both false positives and false negatives while aligning with your operational priorities. Together, these make the core elements of data matching optimization process.
Threshold Tuning Strategies: Controlling Match Acceptance
Field weights determine how much each attribute contributes to a match score. Threshold determine what you do with that score.
Together, weighting and match threshold tuning control whether records are merged automatically, flagged for review, or kept separate.

Why a Single Threshold Doesn’t (Usually) Work?
In complex enterprise datasets, a static, one-size-fits-all threshold almost always fails. This is because data quality varies by source, attributes behave differently across regions or systems, and business risk is not uniform across use cases.
A threshold that works well for customer marketing data may be dangerously permissive for financial records. Conversely, a conservative threshold designed to avoid false positives in regulated workflows can create excessive false negatives elsewhere.
Thresholds must reflect business tolerance for error, not just match score distributions.
Treat Thresholds as Business Controls
Effective threshold tuning starts by aligning thresholds with operational priorities:
- Precision-focused contexts (compliance, finance, identity resolution): prioritize avoiding false positives.
- Recall-focused contexts (marketing, analytics, customer insights): prioritize capturing as many valid matches as possible.
This alignment defines where your initial thresholds should sit, before any technical data matching optimization begins.
A Practical Threshold Tuning Loop
Threshold tuning is not a one-time configuration. It’s an iterative process. Here’s what it typically involves:
- Set initial thresholds based on business tolerance
For example, a precision-heavy workflow might start with a high-confidence threshold (e.g., 90% or above).
2. Run matching and observe outcomes
Review false positives, false negatives, and review queue volumes
3. Adjust thresholds incrementally
Tighten or loosen based on observed error patterns
4. Repeat until outcomes stabilize
The goal is predictable, explainable behavior aligned with business risk.
This feedback loop ensures thresholds evolve with your data, not against it.
Simple, Code-Agnostic Tuning Logic
You don’t need complex algorithms to reason about threshold behavior. With DataMatch Enterprise (DME), you can adjust thresholds per domain or workflow with just a few clicks.
- Too many false positives?
Tighten the threshold or narrow the auto-merge range.
- Too many false negatives?
Loosen the threshold or expand review eligibility.
- Review queue overloaded?
Rebalance thresholds or refine bucket boundaries.
Using Threshold Buckets to Manage Risk
Most mature data matching systems use multiple threshold ranges rather than a single cutoff:
- Auto-merge: high confidence matches that can be safely linked.
- Review queue: ambiguous matches requiring human validation.
- Reject: low-confidence pairs that should remain separate.
This layered approach reduces risk while maintaining scalability, allowing automation where it’s safe and oversight where it’s necessary.
Why Threshold Choice Matters More Than You Think
Threshold tuning is one of the most effective ways to reduce false positives in data matching without sacrificing necessary recall.
Poorly chosen thresholds can dramatically amplify match errors. Even small thresholds shifts can lead to large increases in false positives or false negatives, especially at scale.
When combined with proper field weighting, well-tuned thresholds turn raw match scores into reliable, actionable decisions.
Pattern & Rule Refinement: Encoding Business Logic into Matching
In real-world enterprise data, scores alone are not enough. Accurate matching also requires explicit rules that reflect business logic, known data patterns, and conditions where a match should never occur, regardless of how high the score is.
This is where pattern and rule refinement comes in.
Why Match Rules Matter Beyond Weights and Thresholds
Match scores answer the question, “How similar are these two records?”
Rules answer a different question: “Should these records be allowed to match at all?”
Without rules, matching engines may produce technically “high-scoring” matches that are logically invalid, leading to false positives that thresholds alone can’t prevent. Rules act as guardrails to ensure obvious conflicts, noise, and edge cases are handled before a match is accepted. Fine-tuning match rules allows organizations to encode business logic that prevents known failure modes from recurring.
Common Types of Match Rules in Enterprise Data
Most enterprise matching rules fall into three broad categories:
1. Noise-reduction rules
These rules remove or ignore elements that add similarity without meaning.
- Ignoring legal suffixed such as “LLC,” “Ltd,” or “Corp”
- Normalizing formatting differences in phone numbers or identifiers
This prevents inflated scores caused by generic or non-discriminative terms.
2. Validation and exclusion rules
These rules block matches that violate basic business logic.
- Rejecting matches when country codes conflict
- Blocking customer matches across incompatible regions or regulatory boundaries
Even if names or emails look similar, these conflicts indicate separate entities.
3. Reinforcement rules
These rules require multiple signals before allowing a high-confidence match.
- Requiring both phone number and name similarity
- Enforcing agreement across at least two high-value attributes
This reduces the risk of false positives in sensitive workflows.
Pattern-Based Logic: Reducing Noise at Scale
Rather than handling exceptions one by one, many matching systems use pattern-based logic to encode these rules systematically. Pattern builders allow teams to define reusable expressions that capture real-world data behavior, for example, recognizing common corporate suffixes or validating geographic consistency.
This approach reduces noise without overfitting and allows business rules to evolve as data changes, rather than hard-coding brittle exceptions.
Simple Pseudo-Rule Examples
To illustrate how these rules work in practice, here are a few simplified, code-agnostic example:
- Ignore common legal terms
IF term IN [“LLC”, “LTD”, “CORP”]
THEN exclude from name similarity scoring
- Reject conflicting geographies
IF country_code_A ≠ country_code_B
THEN block match
- Require multiple signals for high confidence
IF name_similarity ≥ threshold
AND phone_similarity ≥ threshold
THEN allow high-confidence match
These rules don’t replace scoring, they shape it, and ensure that matches reflect business reality, not just mathematical similarity.
Why Rules Complete the Tuning Process
Effective data matching isn’t driven by a single lever. Field weights determine importance, thresholds control decisions, and rules enforce logic. Together, they form a layered defense against false positives and false negatives.
With properly refined patterns and rules in place, matching systems become more predictable, explainable, and aligned with real operational needs.
Reducing Review Queue Noise Without Increasing Risk
Even well-tuned matching systems can fail operationally if too many records are pushed into manual review. Review queues are expensive, slow, and often become bottlenecks, especially when they’re filled with low-risk or low-value cases.
Effective data matching tuning doesn’t aim to eliminate review queues entirely. Instead, it focuses on reducing noise, so human effort is reserved for cases that truly require judgment.
Designing Multi-Tier Confidence Buckets
A proven approach is to separate match outcomes into clear confidence tiers, each aligned with a specific action:
- High confidence matches
Automatically merged with no human intervention.
These typically exceed strict thresholds and pass all validation rules.
- Medium confidence matches
Routed to human verification.
These cases contain ambiguity that algorithms alone cannot safely resolve.
- Low confidence matches
Automatically rejected.
Sending these to review adds costs without improving outcomes.
This structure prevents review teams from spending time on records that are either obviously correct or clearly incorrect.
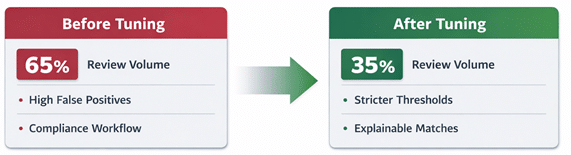
Why Review Volume Is a Tuning Problem, Not a Staffing Problem
When review queues grow, the instinct is often to add more reviewers. In practice, the root cause is usually upstream:
- Thresholds are set too conservatively
- Attribute weights overvalue weak signals
- Rules fail to filter obvious non-matches
Tuning these elements correctly can dramatically reduce review volume without increasing false positives.
Meaningful Quality KPIs for Senior Stakeholders
To evaluate whether tuning efforts are actually working, teams should track metrics that reflect both accuracy and efficiency, such as:
- Percentage of total matches requiring manual review
A direct indicator of operational friction.
- Reduction in false positives over time
Demonstrates whether tuning is improving trust and data quality.
These KPIs connect matching performance to real business outcome, like cost, risk, and speed, rather than abstract accuracy scores.
AI-Assisted Review: Focusing Humans on the Hard Cases
More advanced matching setups use AI-assisted review logic to further reduce noise. Instead of sending all medium-confidence matches to humans, the system can detect patterns that historically cause reviewer disagreement or correction.
This allows review queues to prioritize genuinely complex cases, while routine decisions are handled automatically. The result is a smaller, smarter queue, and faster resolution times.
Why Review Noise Reduction Is a Competitive Advantage
Organizations that control review noise scale their data operations more efficiently. They move faster, spend less on manual effort, and maintain higher trust in their matched data.
Human Feedback Loops: Continuous Learning for Data Matching Tuning
Even the most carefully tuned data matching system will degrade over time if it’s left unchanged. Data evolves, customer behavior shifts, naming patterns change, new data sources are added, and edge cases that didn’t exist six months ago become common.
This is why one-time tuning inevitably fails.
High-performing organizations treat data matching as a living system, not a configuration task. The difference lies in how they use human review.
For instance, if the false positive rate exceeds 5% in a compliance workflow, the system can automatically flag affected match rules for review, prompting recalibration of thresholds or attribute weights.
Human Review Is a Signal, Not Just a Cost
Manual review is often viewed as an operational expense to be minimized. In practice, it’s one of the most valuable sources of insights into where a matching system succeeds or fails.
Every reviewer decision (whether a match is accepted, rejected, or corrected) reveals something about:
- Thresholds that are too strict or too lenient
- Attributes that are overweighted or underweighted
- Rules that no longer reflect real-world data patterns
When captured systematically, this feedback becomes a powerful tuning input.
Building a Closed Feedback Loop
A practical continuous learning loop includes three core steps:
1. Capture reviewer outcomes
Log final decisions on reviewed matches, including overrides and corrections.
2. Feed decisions back into the system
Use these outcomes to adjust:
- Match score distributions
- Threshold boundaries
- Rule logic and attribute weights
3. Iterate on a defined cadence
Apply tuning updates regularly rather than reactively.
This closed loop ensures that tuning decisions are driven by observed behavior, not assumptions.
Why Regular Cadence Matters
Tuning too frequently introduces noise. Tuning too infrequently allows errors to accumulate.
Many mature teams adopt a monthly or quarterly tuning cycle, which provides enough data to spot patterns without overfitting to short-term anomalies. The goal is steady improvement, not constant adjustment.
Tuning for Different Data Domains
Once organizations understand how weights, thresholds, rules, and feedback loops work, they also realize that there is no universal tuning strategy. A tuning configuration that performs well in one domain can terribly fail in another.
The “right” balance between precision and recall depends heavily on the type of data being matched and the business risks attached to it.
Here are some examples of how data matching tuning works for different data domains:
Finance and Compliance: Precision Comes First
In finance, compliance, and risk-sensitive environments, the cost of a false positive is often severe. Incorrectly merging two unrelated entities can lead to regulatory violations, audit failures, or financial loss.
As a result, tuning in these domains typically emphasizes:
- Higher match thresholds
- Heavier weighting of unique identifiers such as email, account numbers, or government-issued IDs
- Conservative auto-merge policies, with more records routed for review
Here, recall is intentionally sacrificed to ensure that any accepted match can be trusted with high confidence.
Marketing and CRM: Balancing Coverage and Accuracy
Marketing and CRM use cases prioritize reach and insight over absolute certainty. Missing legitimate links between customer records can fragment profiles, distort analytics, and reduce campaign effectiveness.
In these environments, tuning strategies often involve:
- Moderately lower thresholds to improve recall
- Greater tolerance for fuzzy matches on names and contact information
- Broader review queues to capture borderline cases
The goal is not perfect precision, but a balanced configuration that maximizes usable coverage without overwhelming teams with errors.
Product and Reference Data: Structure Meets Variability
Product and reference data introduce a different challenge altogether. Attributes such as product names, descriptions, SKUs, and specifications often mix structured and unstructured elements.
Effective tuning here typically relies on:
- Heavy tokenization and normalization
- Hybrid matching strategies combining exact matches (e.g., SKUs) with fuzzy logic (e.g., product titles)
- Domain-specific rules to control noise from descriptive text
In this context, tuning focuses less on entity identity and more on semantic similarity and consistency.
Structured vs. Unstructured Attributes
The nature of the attributes themselves also affects tuning strategy.
- Structured fields (IDs, standardized codes, normalized dates) generally benefit from stricter thresholds and higher weights.
- Unstructured fields (names, addresses, descriptions) require more nuanced tuning, supported by rules, patterns, and contextual validation.
Understanding this distinction helps prevent overconfidence in noisy attributes and ensures that tuning decisions reflect how the data actually behaves.
Tuning Maturity Model: From Static Matching to Adaptive Systems
While tuning strategies vary by domain, organizations also differ in how mature their tuning practices are. Most follow a predictable progression, from static configurations to adaptive, feedback-driven systems.
Understanding this maturity curve helps teams identify where they are today and what improvement realistically looks like.
Stage 1: Static Configuration
At the earliest stage, matching rules and thresholds are set once and rarely revisited. Precision and recall are treated as technical metrics rather than business controls.
Common characteristics include:
- Global thresholds applied across all use cases
- Minimal rule refinement
- Little visibility into error patterns
Accuracy degrades over time as data evolves.
Stage 2: Reactive Adjustment
As issues surface, teams begin adjusting thresholds or weights in response to specific incidents. Tuning becomes reactive rather than systematic.
This stage often includes:
- Manual threshold changes after errors are discovered
- Ad hoc rule additions
- Limited analysis of reviewer feedback
While improvements occur, they tend to be short-lived and inconsistent.
Stage 3: Domain-Aware Tuning
More mature organizations recognize that different datasets require different tuning strategies. Precision and recall targets are aligned with business risk rather than technical ideals.
At this stage:
- Thresholds vary by domain or workflow
- Attribute weights are adjusted based on data behavior
- Review queues are actively managed to control operational load
Matching accuracy becomes more predictable and defensible.
Stage 4: Feedback-Driven Optimization
At the highest level of maturity, tuning is continuous and evidence-based. Human review decisions are systematically captured and fed back into the matching system.
Key traits include:
- Regular tuning cycles based on observed outcomes
- Ongoing refinement of rules, weights, and thresholds
- Measurable improvement over time without increased review burden
Here, data matching is no longer a configuration task; it’s an adaptive control system that evolves alongside the business.
Why this matters
Organizations don’t fail at data matching because they lack algorithms. They fail because they treat tuning as static, universal, or secondary.
The most effective teams understand:
- Tuning is domain-specific
- Accuracy is contextual
- And sustained performance requires continuous learning
That mindset is what separates acceptable matching from truly reliable outcomes.
How Data Matching Tuning Improves Business Outcomes
Data matching tuning is often discussed in technical terms. For senior stakeholders, however, tuning only matters if it improves measurable business outcomes.
Well-tuned matching systems don’t just produce cleaner data. They change how efficiently teams operate and how confidently decisions are made.
Reduced Manual Review Workload
One of the most immediate benefits of tuning is a decline in unnecessary manual reviews. By tightening thresholds where precision matters and refining rules that filter obvious non-matches, organizations can significantly reduce the volume of records routed to human verification.
Fewer low-value reviews mean:
- Lower operational costs
- Faster processing cycles
- More reviewer time spent on genuinely ambiguous cases
Improved Decision Confidence
False positives erode trust. When teams aren’t confident that records truly represent the same entity, downstream decisions become cautious or delayed.
Tuned matching improves confidence by ensuring that:
- High-confidence matches are truly reliable
- Merged records can be safely used in reporting, compliance, and operations
- Exceptions are visible and explainable
This trust is especially critical in regulated and high-risk environments.
Faster Time to Insight
Accurate matching accelerates analytics. When entities are correctly linked, reporting systems no longer need manual correction, reconciliation, or caveats.
As a result:
- Customer and entity views stabilize earlier
- Analytics teams spend less time fixing data
- Insights reach decision-makers faster
Speed here is not about processing time alone, it’s about eliminating friction across the data lifecycle.
Lower Operational and Compliance Risk
Poorly tuned systems expose organizations to avoidable risk. False positives can trigger compliance failures, while false negatives can hide meaningful relationships.
Tuning reduces risk by:
- Aligning precision levels with business tolerance
- Making matching behavior predictable and auditable
- Reducing reliance on informal workarounds
Risk decreases not because errors disappear, but because they are controlled.
Indicative Impact of Effective Tuning
While results vary by domain and data quality, organizations that invest in structured tuning commonly observe improvements like:
| Outcome Area | Typical Impact Range |
| Manual review volume | 20–40% reduction |
| False positive rate | 10–30% decrease |
| Match acceptance confidence | Noticeable improvement |
| Time to usable analytics | Shortened reporting cycles |
These gains compound over time as feedback loops mature and tuning becomes continuous rather than reactive.
Why DataMatch Enterprise is the Right Choice for Enterprise Data Matching
In enterprise deployments, teams often see the biggest gains after their first two tuning cycles, when reviewer feedback exposes recurring false-positive patterns that static rules miss.
DataMatch Enterprise (DME) provides the control and flexibility to manage these tuning cycles effectively, ensuring that improvements compound over time and deliver measurable results.
Rather than forcing teams into rigid, one-size-fits-all matching logic, DME allows organizations to tune matching behavior based on real operational needs. Teams can adjust thresholds by use case, assign meaningful weights to attributes, refine match rules using pattern-based logic, and continuously improve accuracy using reviewer feedback.
Key capabilities include:
- Advanced threshold tuning to control precision and recall by domain
- Pattern Builder–based rule refinement to reduce noise from common terms and conflicting signals
- Multi-tier confidence buckets to optimize auto-merge, review, and rejection flows
- Feedback-driven optimization to ensure matching accuracy improves as data evolves
Customers using DataMatch Enterprise have reported measurable improvements such as:
- Reduced manual review volumes
- Lower false positive rates in high-risk workflows
- Faster time to trusted analytics and reporting
For organizations where data accuracy directly impacts risk, efficiency, and decision-making, tuning isn’t critical to ensure data matching accuracy.
If your team is struggling with overloaded review queues, inconsistent match decisions, or growing manual verification costs, data matching tuning can’t remain theoretical.
You need tooling that lets you adjust thresholds, weights, and rules in response to real review outcomes, without rebuilding your data stack. DataMatch Enterprise is designed for teams that need to reduce review noise while maintaining confidence in every automated match.
Request a demo or start a free trial to see how DME can improve your matching outcomes.
Frequently Asked Questions
1. What is data matching tuning?
Data matching tuning is the process of adjusting match thresholds, attribute weights, and match rules to improve accuracy, reduce false positives, and align matching behavior with real business risk.
2. How does threshold tuning reduce false positives?
By setting appropriate confidence levels for different attributes and workflows, threshold tuning prevents unrelated records from being incorrectly merged, and thus, helps reduce false positives in data matching.
3. What causes false positives in data matching?
False positives occur when unrelated entities share similar attributes, like common names or emails, and are merged incorrectly due to insufficient weighting, rules, or thresholds.
4. How often should match rules be tuned?
Match rules should be revisited regularly, ideally monthly or quarterly, depending on data volume and rate of change, to ensure the system adapts to evolving data patterns.
5. What’s the difference between match thresholds and attribute weights?
Thresholds control when records are considered a match, while attribute weights determine the relative importance of each field in calculating a match score. Both work together to improve data matching accuracy.

