































1.0 Executive Summary – The AML Compliance Dilemma
AML compliance programs demand accurate and timely information. Yet, 87% of organizations’ financial crime risk management processes and systems are only, at best, ‘somewhat,’ efficient. Poor data quality, disparate data sources, manual matching & screening processes, and the high rate of false positives are some of the leading causes of poor compliance with AML regulations.
The past few years have seen a rise in anti-money laundering (AML) pressures across the world as leaks like the Panama Papers led to high-profile laundering cases. With laws getting refined and more stringent, the costs and fines for being AML non-compliant have also become significantly higher.

Since 2013, financial institutions failing to meet AML rules for KYC have been fined more than $10 Billion
The uptick in money-laundering scandals continues to rise, yet, as always, financial institutions continue to struggle with AML compliance and risk-management challenges. While there are many reasons for this, experts agree that AML compliance processes and systems at many financial institutions have grown too large and too clumsy to be able to react swiftly to a fluid and dynamic economic environment. The internet with its blockchain technology poses an even greater challenge for banks as they try to deal with tech-empowered financial crimes.
Preventive measures against financial crimes are a distant hope as institutions continue to struggle with basic activities such as accurate name and list matching. Even now, despite all the progress in AI and automation, organizations still spend days manually matching, screening, and investigating each false positive case. Ironically, the technologies used in these institutions result in high false positives causing banks to increase their investigative task force and spending up to billions of dollars just to resolve false positive cases.
Another challenge that financial institutions cannot tackle in due course is poor data quality from disparate data sources. Data entry in banks is mostly still a manual process. Duplicated, inconsistent data formats and standards, or data stored in multiple ways across multiple sources are challenges at the root level that institutions have yet to overcome.
AML compliance is becoming a mounting pressure, one that institutions must prepare to take on by first resolving ground-level problems. It is only when data quality is optimized, manual processes are automated, and modern technologies are employed that institutions can meet AML regulations and ensure the safety and integrity of their customer data.
2.0 Current System Limitations and State of Investigations
AML compliance is not restricted to one country or region. As international transactions are picking up pace with online payments, e-commerce, and digital businesses, institutions must follow global AML regulations.
Firms are required to have adequate systems and controls in place to ensure that criminals, terrorists, and terrorist financing organizations are accurately identified and reported to relevant authorities. For this purpose, firms have to be compliant with global regulations such as the EU’s Fourth Money Laundering
Directive, the USA PATRIOT Act, the Know Your Customer (KYC), the Counter Financing of Terrorism (CFT), and many more.
Firms also have to ensure they meet their local and national regulations to curb financial crimes at ground level. This means there are watchlists against which customer data must be matched. Not doing so could lead to hefty fines and penalties.

PayPal’s example is perhaps one of the most popular in the financial world. The organization was fined pay $7.7 million to settle charges by the U.S. Treasury Department’s Office of Foreign Assets Control that it violated trade sanctions against Iran, Sudan, and Cuba.
Customer data screening, however, is a difficult task to achieve if the firm’s data quality does not meet basic quality benchmarks. For instance, most firms today suffer from:
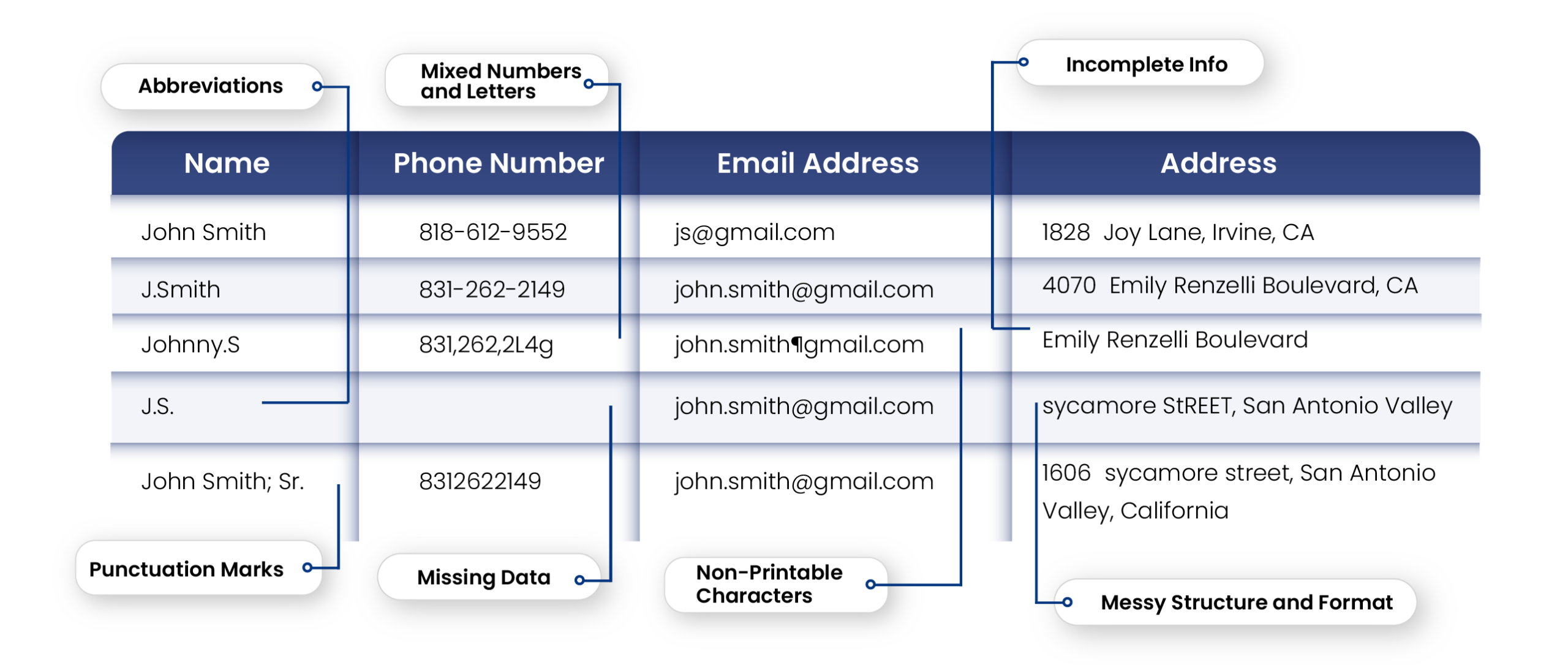
 Poor quality data such as misspelled names, typos, lack of standardization, duplicates, and fake information. This is a common problem when foreign names need to be registered. It’s not uncommon for an Arabic name like, ‘Abdul Razaaq,’ to be written as, ‘Abul Razak’ or ‘Abu Razak.’ Many banks are still making 10s of thousands of costly customer calls every month to verify information and update incorrect or missing information in the database.
Poor quality data such as misspelled names, typos, lack of standardization, duplicates, and fake information. This is a common problem when foreign names need to be registered. It’s not uncommon for an Arabic name like, ‘Abdul Razaaq,’ to be written as, ‘Abul Razak’ or ‘Abu Razak.’ Many banks are still making 10s of thousands of costly customer calls every month to verify information and update incorrect or missing information in the database.
Data streaming in from multiple entities, subsidiaries, and vendors. Without a data consolidation system in place, firms cannot create a single view of the customer, which is necessary for identity resolution.
The lack of automated solutions, systems, and processes that can help firms with identity resolution and risk identification. False positives remain one of the most time-consuming challenges.
Out-dated technologies rely on rules-based tasks that are unable to perform intelligent matching routines and miss out on context.
Not all customer data (historical or current) is currently available in digital format;
Due to acquisition activity, legacy systems exist that are siloed and/or cannot handle the increased demands of compliance due to their inherent limitations.
Institutions that make use of AML technologies don’t fare any better. While they can perform complex name matching against multiple sources and lists, the results are far from accurate.
False positives, matches produced by the system that, following subsequent investigation turn out to be wrong, receive the most attention. Hypothetically, if the average rate for false positives is 5% for a data set of 100,000 records, that is 500 match alerts which analysts will have to spend time investigating. False positives lead to an excess of administrative work because they must be investigated as thoroughly as a real match.
False negatives, where a potential match is missed completely even riskier: first, because the matches don’t trigger any results, the record cannot be confirmed and second, the information is never reviewed because no one even knows it exists.
Time, money, and resources are spent on investigating false positives, while false negatives remain an underlying threat.
As the transaction volume and money transfer activity increases, firms are grappling to resolve too many demanding problems at once. Employing more risk analysts, more AML departments, and resources only increases the cost, without resolving key problems.
Hence, firms will need to invest in new software with sophisticated time-saving matching algorithms that recognize variants or misspellings of names, use established fuzzy matching algorithms to deal with the various nuances of data and empower firms to augment scattered data for better screening results.
3.0 Name-Matching Technology as a Critical Challenge to AML Compliance
Matching algorithms are the key to effective name matching. For instance, an efficient name-matching technology must be able to identify:
different spelling of names e.g. ‘Jon’ instead of ‘John’, ‘Elisabeth’ or ‘Elizabeth’ shortened names e.g. ‘Elizabeth’ matches with ‘Elisa’, ‘Elsa’, ‘Beth’, ‘Betty’, etc. insertion/removal of punctuation and spaces name variations name reversal inadvertent misspellings deliberate misspellings phonetic spellings abbreviations e.g. ‘Ltd’ instead of ‘Limited’

Moreover, it must be able to find duplicates and allow the easy purging of such duplicates before the data set is used for matching with a watch list.
The simplest solution used by various institutions today is, ‘exact hit,’ matches which is quite useless in the face of complex, real-world data. Firms need solutions that offer fuzzy matching as the key algorithm to determine the similarity between multiple data elements such as business names, titles, address information, and more.
The fuzzy logic uses a combination of algorithms to detect and evaluate near matches rather than on exact matching. These algorithms cater to a multitude of challenges in a database. For instance, the strings “Kent” and “10th” may be considered 50% similar, based on character count and phonetic match.
With real-world data becoming increasingly complex, firms need more than exact matching to detect hidden identities. Moreover, since launderers use different techniques to bypass filter detection, a powerful fuzzy-matching system will be able to catch on what simple exact filters may miss.

Accurate screening relies upon non-exact complex fuzzy matching because criminal elements targeting organizations often transpose names, dates of birth, and other personal information to attempt to conceal their true identity.
4.0 Choosing an Identity Resolution Product
For AML compliance, firms must consider a solution that allows them the ability to perform identity resolution while overcoming challenges posed by poor data quality. The ideal solution must be able to reduce the rate of false positives and negatives and must return a high match accuracy without compromising on time and efficiency. Additionally, the product must have:


Cross-jurisdictional data matching capabilities allow for matching across multiple data sets with the ability to integrate data from varying sources.

Proprietary algorithms that can cope with real-world data, i.e. data that is not formatted or cleansed and that may include missing characters, nonstandard data, initials, codes, etc.

Data consolidation and survivorship abilities allow the firm to get a consolidated, single-customer view to understand contextual relationships.

Support for server and API integrations while also being low on maintenance.
Firms need to have a clear understanding of any matching software used, including any limitations. The parameters should be tested and calibrated in line with the risk appetite of the firm. Measures should be in place to ensure that it remains effective. Calibrating an identity resolution software’s matching capability to the appropriate or required level of matching accuracy is a key tool against fighting financial crime.
5.0 Using Data Ladder as a One-Stop Solution for AML Challenges
False positives, matching inconsistencies, and non-standardized, disparate data sources are all variations of a data quality problem. Thus, the solution to them must lie in one platform.
Generally, businesses target one aspect of a problem and rush to bring in a solution to tackle that specific problem. For instance, because name-matching is the first challenge, businesses will only look for data-matching solutions that can return them a high match. However, data match software, no matter how powerful, cannot return a high match if it does not allow for standardization and cleaning of data.
This means the firm will have to acquire a separate data cleansing solution. Once the data is cleansed and standardized in Solution A, it will be passed on to Solution B for matching, verification, and validation. Then it might be passed on to Solution C for visual analytics or enrichment.
Not only does this lead to an inefficient process, but it makes the problem further complicated.
Recognizing these current issues, inefficiencies, and limitations, Data Ladder is empowering firms to assess the quality of their customer data, clean and standardize it, and eventually match with the screening component to return accurate matches – all made possible on one, on-premises platform.
With DME, firms can perform critical actions such as:
Cross-jurisdictional matching with global AML Regulations: Key elements of AML solutions include:
Know your customer (KYC) Customer due diligence (CDD) Suspicious activity monitoring Case management services Watch-list filtering Record-keeping Customer behavior
Firms will need to match their customer data across several lists at a time depending on their country’s rules and regulations. DataMatch Enterprise allows for cross-jurisdictional data matching across multiple data sources at a time, saving businesses time and effort.
Integration of Data from Over 500 Sources: Because financial firms have multitudes of disparate data sources, they will need integration abilities to connect those sources onto one platform. DME allows for the integration of over 500 data sources with no additional third-party plugins or connectors (unless required or requested).

Lower False Positives: In an ordinary instance, an exact match solution may return someone living in Kerman, California as a match to someone living in Kerman, Iran. An intelligent solution will be able to counter this detection, by allowing for smart filters. The ability to create smart rules or patterns to filter data based on specific conditions will prevent such false positives from happening.
Capture False Negatives: DME uses a combination of proprietary and fuzzy matching algorithms to detect even the most skeptical of matches. Because of this, records of which exact filters would have been missed can now be captured. False negatives are the leading cause of AML fines. The failure to identify a sanctioned entity can be dire for a financial institution. For instance, an entity named Inter Global Holdings Limited may not be detected by a legacy system if it’s written as IBH or IBHL.
Clean and standardized data: New York was written as NY, NYC, N.Y. While this may seem like a mere spelling problem, it poses a significant roadblock when the data has to be matched with a sanction list. This type of non-standardized data must be standardized to an established format to be fit for a data match activity.
Remove Duplicates: Duplicates cause a significant problem for databases and are largely responsible for false positives. It is imperative to clean the data from duplicates before it is used to match with sanction lists.
Save up to 80% Time and Efficiency: With a powerful, multi-purpose solution like DME, risk analysis teams can save up to 80% of their time in manual screening and dealing with false positives. This will enable them to utilize their time for deeper investigations of real cases.
Work on a secure, on-premises solution: AML screening is a confidential operation and requires a safe, secure, on-premises system that remains in the control of the firm. DME offers a desktop and a server + API edition so large enterprises can remain in control of their data while performing required operations.
Whether your organization is struggling with poor customer data quality, or with data spread across disparate sources, our solution can help you improve and build more efficient, effective, and sustainable processes; enabling your firm to meet AML regulations better, and faster.

6.0 The Ultimate Question – How Can a Firm Lower False Positive Rates & Be AML Compliant?
Financial institutions will continue to be pressured to screen transactions and customer lists for the likes of terrorists and trafficking criminals, but without the right plan, tool, or process, they will continue to be at risk of failure.
To mitigate false positives and to ensure AML compliance, firms will have to do more than just rely on manual labor to sort out cases. It will need to:
Prioritize Data Quality
As in all financial crime and compliance management (FCCM) solutions, poor data quality causes multiple issues (garbage in garbage out rule). For example, there could be a customer firm called “Anti Bribery & Corruption Inc.,” which would match against a list entry called “ABC” based on an initials-only match. If a firm’s data is inherently chaotic, messy, and dirty, it will need to implement a data quality process that caters to problems such as:
Human errors at the time of data recording. The lack of training and understanding of data quality and its implication on downstream processes. Legacy systems where there are limited data controls, increase the chances of duplicates and errors. Siloed data sources that lead to disparate information. The lack of established standards in recording, verifying, and validating customer data. The reliance on outdated technology to somehow miraculously manage modern, real-world data.
Apply Business Intelligence Solutions
Financial institutions manage huge amounts of banking data, and more data sets are being recorded daily. The growth of financial data collected far exceeds human capabilities to manage and analyze them efficiently in a traditional style. They need to apply new business intelligence solutions because traditional statistical methods cannot analyze large data sets. Firms will need to invest in data mining solutions used to solve business problems in patterns, causalities, and correlations in financial information that are not apparent to managers because of the volume of data.

Consistently Clean and Fine Tune Data
Firms must develop preventive goals. This starts with consistently fine-tuning and optimizing the quality of data to maximize efficiency at the time of matching. This mitigates unnecessary hits and establishes the balance between true matches and false positives. There are no specific tuning methods, as it depends on multiple factors such as type of business, volume, location, etc. However, regularly performing a data quality assessment check, reviewing client information, and applying tuning techniques such as back-testing and logistic regression will help prepare the data when it will need to be matched against a sanction list.

Investing in the Right Tools and Technologies
Manual screening slows down the process significantly. In the current world scenario, where 2 to 5 percent of global gross domestic product (GDP) is laundered annually, equalling close to 800bn USD to $2 trillion firms can no longer afford a delay in being AML compliant.

Almost 50% of Companies Have Been Victims of Financial Crime.
The pressure is real, yet, the financial industry is slower than others to incorporate automation technologies to perform their most crucial operations. This is not to say that a trained risk analyst is not valuable – rather the human resource should be empowered by a solution that can take away the routine task and leave them with the time to focus on deep investigations.
Strategic planning, technology overhauland, and data quality training are some of the key implementations that will help financial institutions race against time and prevent money launderers from causing more havoc.
Conclusion
Financial institutions’ compliance and control functions are being asked by businesses and regulators to search through mountains of account and transaction information for certain individuals, entities, and/or sanctioned jurisdictions. To make this possible, firms will need more than just a simple AML software to find matches. It will need a one-stop platform where challenges of data quality, data duplication, complex matching, and consolidation can be resolved.
It will need an overhaul of processes, systems, and technologies that are more of a liability and cause an increase in manual labor. In an age of technological advancements, financial firms must not let outdated systems pull them down.
Firms can improve their AML compliance processes by implementing new software with sophisticated time-saving matching algorithms that recognize different variants or misspellings of names and thus reduce the number of false positives to a minimum. Other approaches include intelligent automation workflows, robust management and audit controls, implementing industry best practices, and gaining the technical ability to analyze past sanctions screening results.
Want to know how we can help your firm meet AML compliance regulations?


