































Last Updated on April 16, 2026
An average enterprise – with 200-500 employees – uses about 123 SaaS applications to digitize their business processes. With large amounts of data being generated every day, you definitely need a systematic way to handle data. This includes adopting modern practices and strategies to capture, process, share, store, and retrieve data while minimizing data loss and errors. Any loopholes present in these processes can endanger your business with serious risks.
In this blog, we discuss what data management means and key principles of data management that you must know while managing your organizational data. Let’s get started.
What is data management?
Data management is the practice of adopting principles, rules, strategies, and methodologies that can help ensure maximum and optimal utilization of an organization’s data.
The data management concepts and principles are pretty diverse as they focus on a number of data processes at an enterprise, such as:
- Data capture and integration: Ensures that the required data is captured, integrated, and consolidated so that it can be used for all intended purposes.
- Data storage: Ensures that data is stored wherever needed – whether it is an on-premise storage, public or private cloud, or a hybrid setup.
- Data security: Ensures that data is safe from unauthorized access, and policies are implemented for secure data access and sharing.
- Data quality management: Ensures that data is continuously profiled for errors and is run through a data pipeline for data quality checking and fixing.
- Data availability: Ensures that data is accessible to people whenever they need it, and there are backup and disaster recovery plans in place.
8 Principles of Data Management
Designing your data management processes can be difficult since it focuses on a variety of data domains. Here, you will find out what data management principles are as we see the top 8 data management principles that you need to administer.
1. Data Modeling
The first and foremost data management guiding principle is data modeling. Data modeling means designing and structuring your data assets, their properties, and their inter-relationships in a logical manner. An example data model for a retail business is shown below:
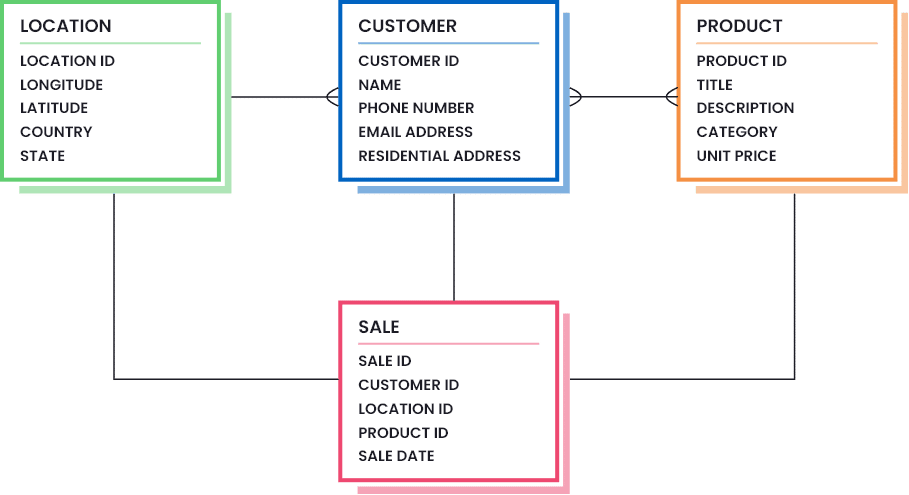
A data model simply represents the following (as can be seen from the diagram above):
- The data assets that an organization stores and manages (for example, Customer, Product, Location, and Sales),
- The real-world properties that each asset stores (e.g.: Customer data asset has the customer ID, Name, Phone Number, Email Address, and Residential Address),
- The data type and size of each property (for example, Customer ID should be an integer with a maximum number of 12 digits),
- The relationship constraints that two or more data assets have between each other (for example, Customer has Location, Customer buys Product, etc.)
- The relationship cardinality that shows the maximum number of relations one asset can have with the other (for example, one Customer can only have one Location at a time),
- The referential integrity that defines which records can be referred across assets (for example, a Sales record must always refer to a Customer ID that exists in the Customer table).
An organization can never manage its data efficiently if it fails to accurately relate data requirements to the structured data models. For this reason, it is important to collect data requirements first from necessary stakeholders and then start the design process. Once you know the expectations that your team has from the data they use, you can then design data models that capture the required information.
2. Data Roles and Responsibilities
Business leaders often make the mistake of holding data users responsible for efficient data management. But in reality, you need to appoint various data professionals at different levels at your company. This ensures that all efforts and investments made for data management are not just implemented, but well-maintained for years to come. Let’s take a look at the most important data roles and their responsibilities that you must consider while building a data team.
- Chief Data Officer (CDO): A Chief Data Officer (CDO) is an executive-level position, solely responsible for designing strategies that enable data utilization, data quality monitoring, and data governance across the enterprise.
- Data steward: A data steward is the go-to guy at a company for every matter related to data. They are completely hands-on in how the organization captures data, where they store it, what it means for different departments, and how its quality is maintained throughout its lifecycle.
- Data custodian: A data custodian is responsible for the structure of data fields – including database structures and models.
- Data engineer: A data engineer is responsible for data modeling and building systems that accurately capture, store, and analyze data.
- Data analyst: A data analyst is someone who is capable of taking raw data and converting it into meaningful insights – especially in specific domains. One main part of data analyst is to prepare, clean, and filter the required data.
- Other teams: These roles are considered to be data consumers, which means they use data – either in its raw form or when it is converted into actionable insights, such as sales and marketing teams, product teams, business development teams, etc.
3. Data System Design
This is another important aspect of data management that helps you to figure out:
Where and how is data collected, integrated, and hosted to ensure maximum data utilization and availability and minimum data loss and downtime?
Data system design refers to multiple disciplines, such as data sources, architecture, synchronicity, and hosting. Let’s take a look at what each of them covers:
a. Data inlets and outlets
The first part of system design is identifying sources of data inlets and outlets – from where data is captured and where is it transferred to. Organizations use multiple applications to capture data, such as website trackers, marketing automation, CRMs, accounting software, webforms, etc. You need to identify all such sources and see how data is transferred between sources or to a new destination.
b. Data system topology
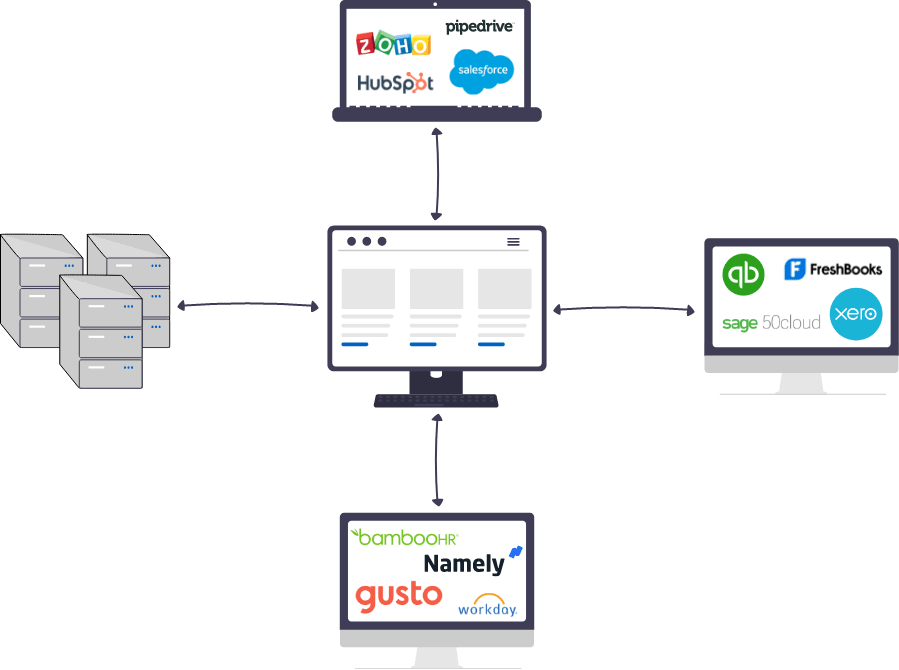
Data topology refers to how the data systems are interconnected with one another. At a high-level, you can design your topology using one of the following approaches:
- Centralized approach where every data system connects to a central, intelligent hub,
- Decentralized approach where data systems talk to each other to get the required information.
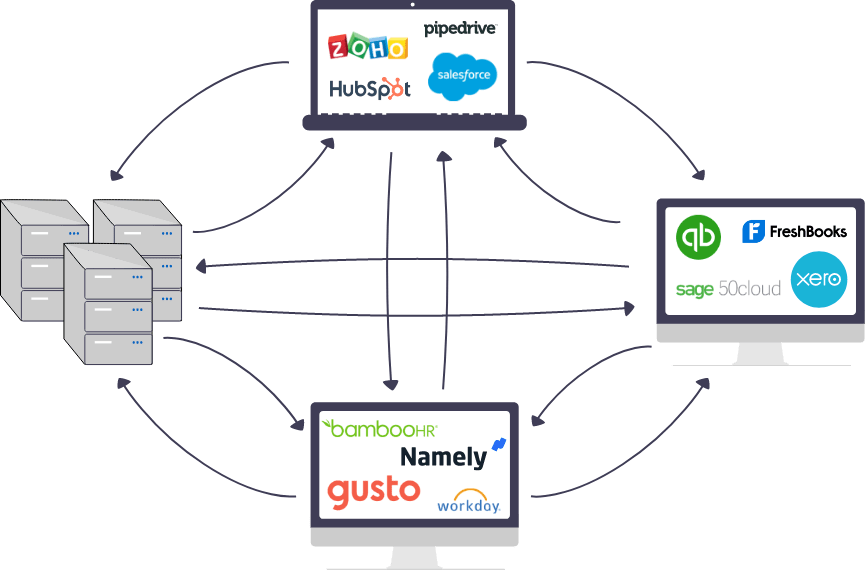
c. Data synchronization
This refers to how data is kept updated across sources. Data management systems, especially MDM solutions, are implemented in different architectural styles, depending on the organization’s requirements. The most common architectural styles for synchronization include:
- Consolidated style
- Data coming from various sources is fed to a central hub that stores a consolidated view of data, but does not transfer it back to source systems. Any BI or downstream applications can fetch data from the central hub as needed.
- Co-existence or hybrid style
- Data coming from various sources is fed to a central hub that stores a consolidated view of data, and the updates are also transferred to all connected source applications.
- Centralized style
- Data coming from various sources is fed to a central hub that stores a consolidated view of data, but does not transfer it back to source systems. However, the source systems can query the updated data as needed from the central hub.
d. Data hosting
This refers to where the data is hosted or stored. Depending on an organization’s needs, data can be stored locally on premises, or saved on public or private cloud. You can also opt for a hybrid setup where some data is kept on-premise while some is hosted on cloud.
4. Data Quality
One of the main aspects of data management is data quality management. The presence of intolerable defects in your dataset shows that the required data management practices are not in place. If your teams cannot trust the data they have, it affects their work productivity and efficiency. To prevent data quality errors from entering into the system, you need to treat incoming data to data pipelines where a number of operations are performed, such as data cleansing, standardization, and matching.
a. Data quality measurement
Data quality is usually indicated in datasets through a number of data characteristics. These are usually called data quality dimensions. The most common data quality indicators include:
- Accuracy: Data depicts reality and truth.
- Validation: Data is present in the correct pattern and format, and belongs to the correct domain.
- Completeness: Data is as comprehensive as needed.
- Currency: Data is up-to-date or as current as possible.
- Consistency: Data is the same (in terms of meaning as well as representation) across different data sources.
- Identifiability: Data represents unique identities and does not contain duplicates.
- Usability: Data is present in a format that is understandable by the ones who intend to use it.
b. Data quality management
To smoothly adopt data quality management principles, you must implement a number of data quality processes, such as:
- Data profiling to assess the current state of your data and identify cleaning opportunities,
- Data cleansing and standardization techniques to attain a standardized view across all data sources,
- Data matching to identify duplicate records representing the same entity,
- Data deduplication to eliminate duplicate records,
- Data merge purge to consolidate duplicate records into one and overwrite data wherever needed and attain the golden record.
Need to improve data quality across systems?
Use Data Ladder to profile, standardize, match, and deduplicate data before poor quality affects reporting, operations, or trust.
Start a Free Trial5. Data Governance
The term data governance refers to a collection of roles, policies, workflows, standards, and metrics, that ensure efficient information usage and security, and enables a company to reach its business objectives. Data governance relates to the following areas:
- Implementing roles-based access control to ensure that only authorized users can access confidential data,
- Designing workflows to verify information updates,
- Limiting data usage and sharing,
- Collaborating and coordinating on data updates with co-workers or external stakeholders,
- Enabling data provenance by capturing metadata, its origin, as well as updating history.
Want more control over data quality and governance?
Data Ladder helps teams improve data consistency, reduce duplicates, and support better governance across enterprise systems.
Start a Free Trial6. Data Education
You can perfectly design data models, data systems, and data quality frameworks, and take care of all basic principles of data management but still fail at achieving your data goals – and the main culprit behind this is lack of data education amongst your team members. If your team does not understand how data systems work in your organization, they will probably mishandle it or use it inefficiently.
To enable data literacy amongst your team members, you must start by documenting everything. And spread that knowledge through learning plans that highlight various data aspects, such as:
- What it contains,
- What each data attribute means,
- What are the acceptability criteria for its quality,
- What is the wrong and right way for entering/manipulating data?
- What data to use to achieve a given outcome?
Furthermore, these courses can be created depending on how frequently certain roles use data (daily, weekly, or yearly).
7. Data Protection
Data protection strategies encompass some of the most important security measures. The three main areas that fall under data protection include:
- Data security: Safeguarding data from malicious attacks manipulation,
- Data access control: Controlling who can access data and when,
- Data availability: Ensuring data is backed up and restored in case of data loss or unavailability.
The terms data protection and data security are often used interchangeably, but they both actually refer to slightly different concepts. Data protection relates to protecting data from loss, damage, or corruption, and ensuring data availability, while data security relates to safeguarding data from malicious attacks and manipulation.
However, both are crucial to enable quality data management.
8. Data Compliance
Data compliance standards (such as GDPR, HIPAA, and CCPA, etc.) are compelling businesses to revisit and revise their data management strategies. Under these data compliance standards, companies are obliged to protect the personal data of their customers and ensure that data owners (the customers themselves) have the right to access, change, or erase their data.
Apart from these rights granted to data owners, the standards also hold companies responsible for following the principles of transparency, purpose limitation, data minimization, accuracy, storage limitation, security, and accountability. It is very difficult to comply with these standards if the underlying data is not well-managed. And a lack of compliance can limit your business operations – especially geographically.
Wrap up
And there you have it – the top 8 data management principles you must adopt to maximize data effectiveness throughout your organization. Since data is an integral part of a business, data management done right helps you to achieve your goals and objectives efficiently and easily.
If your business has not yet adopted any data management principle, it is okay to start at one place and potentially grow across disciplines as things fall into place. Data quality management is one such area that can have a major positive impact in the least amount of time.
Having delivered data cleansing and matching solutions to Fortune 500 companies in the last decade, we understand the importance of keeping data free from errors. Our product, DataMatch Enterprise, helps you to clean and standardize your datasets, and eliminate duplicate records that represent the same entity.
You can download the free trial today, or schedule a personalized session with our experts to understand how our product can help implement the best practices for attaining and sustaining data quality at an enterprise level.
Ready to put better data management into practice?
Try Data Ladder to clean, standardize, and match data for more reliable enterprise records.
Start a Free Trial
