







































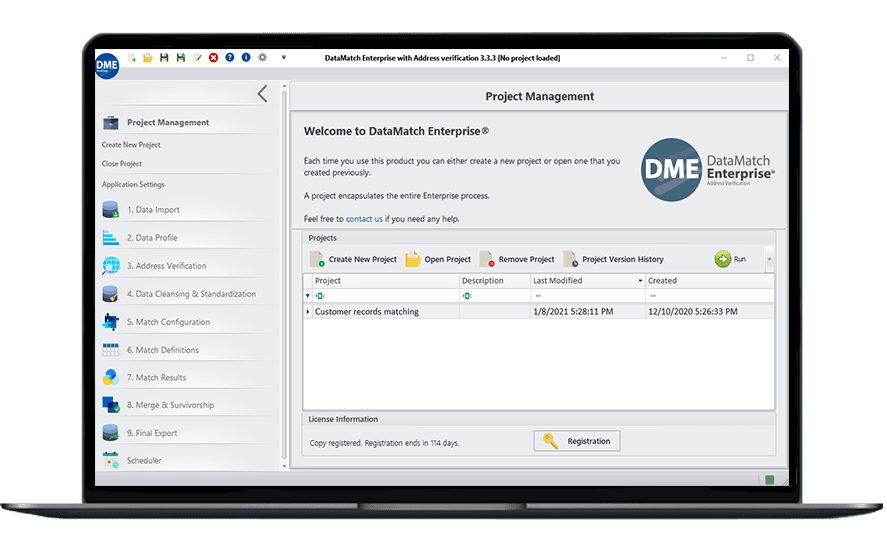






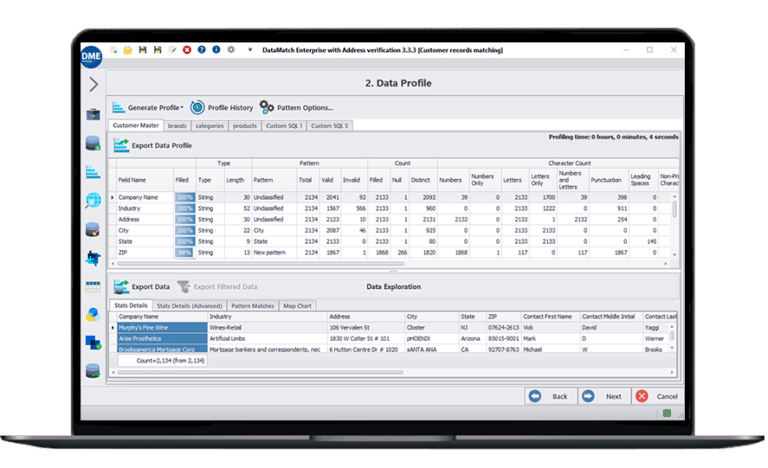
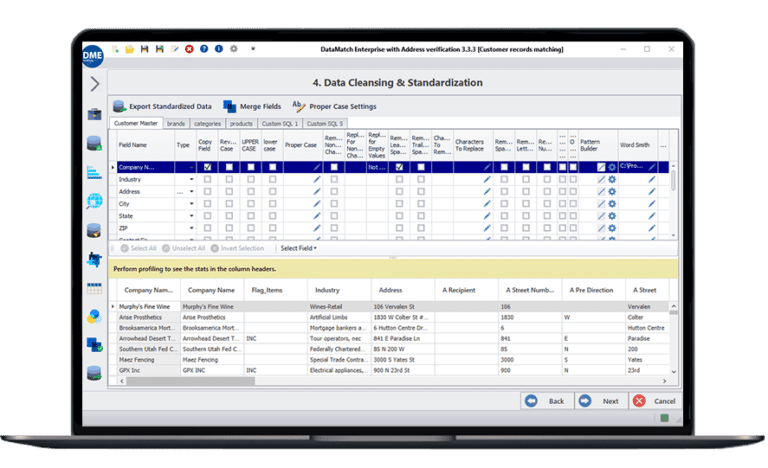
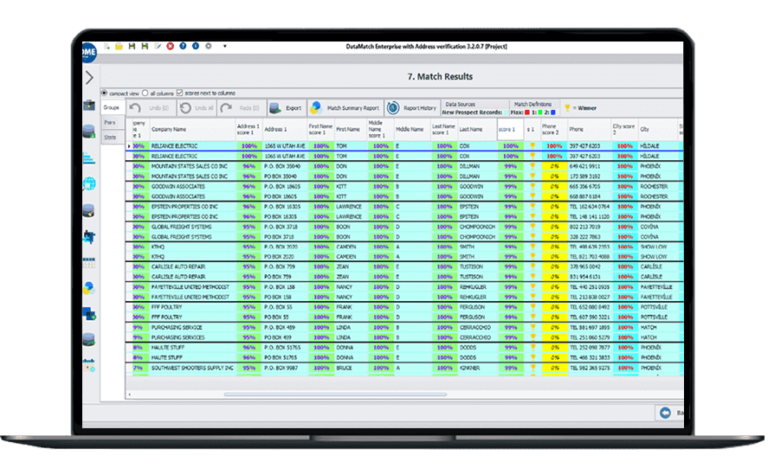

High performance
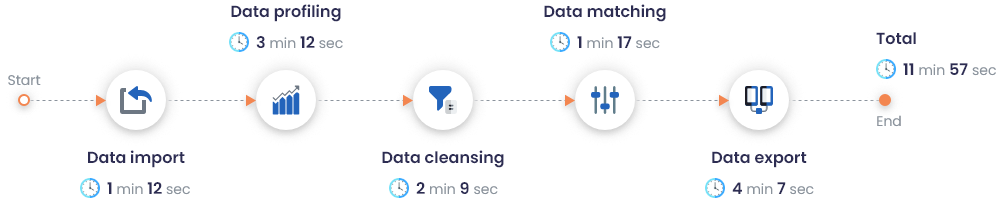
Exceptionally high performance and scalability features, allowing tons of data to be cleansed, matched and processed on demand.

Quick implementation
Simply download and deploy the application within minutes with the help of our guided installation wizard and start matching.
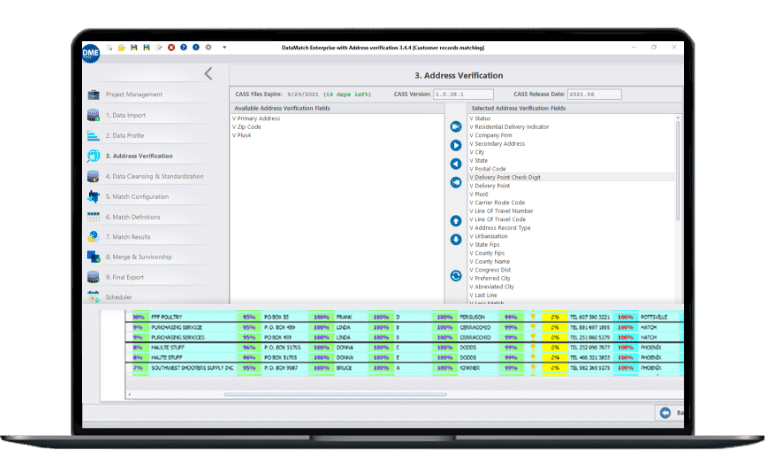
Intuitive interface
A highly visual and intuitive interface made for business users, IT specialists, data analysts and scientists, as well as novice users.

Robust matching technology
Rated faster and more accurate than IBM and SAS, DME consistently had the least number of false positives in independent studies.

Seamless integration
Readily integrate the world’s fastest and most accurate data quality features into your custom-built or third-party applications.
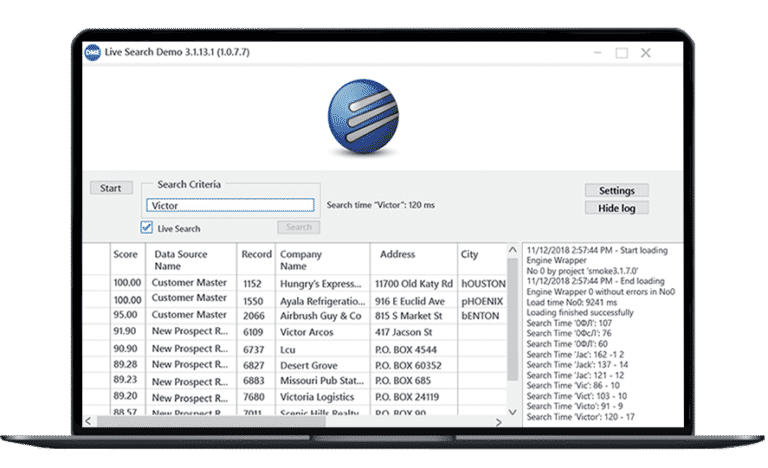
Real time syncs
Compute exact, fuzzy, and intelligent matches in real-time, across and within multiple data sources at blazing speeds.

Quick data profiling
Master record selection
Workflow orchestration
Advanced filtering

Instant and live data preview

Record Linkage and Deduplication

Phone number standardization

Bulk cleansing and standardization

Email address cleansing
Seamless data integration
Cross-column matching

Pattern matching and recognition

It’s not just the software which works very well for us, but the focus and knowledge that Data Ladder brings to the table


Thanks to Data Ladder we successfully cleaned up and matched our internal sales file with new leads, greatly improving efficiency and sales.

We could not do these reports before. Now, DataMatch has become a main staple in my suite of tools that I work with


Merging Data from Multiple Sources – Challenges and Solutions

Big Data Analytics Is Booming – But Is Your Data Ready for It?
Amazon generates 35% of its revenue from data-powered recommendations. Netflix enjoys an 89% retention rate by personalizing every experience using viewer behavior, preferences, and interaction

Data Ethics in the Age of AI: Why Responsible Matching Matters More Than Ever
When AI systems deliver inaccurate or inequitable results, many people immediately assume that something went wrong in the algorithms. Rarely do we look upstream –
Big Data Analytics Is Booming – But Is Your Data Ready for It?
Amazon generates 35% of its revenue from data-powered recommendations. Netflix enjoys an 89% retention rate by personalizing every experience using viewer behavior, preferences, and interaction
Data Ethics in the Age of AI: Why Responsible Matching Matters More Than Ever
When AI systems deliver inaccurate or inequitable results, many people immediately assume that something went wrong in the algorithms. Rarely do we look upstream –

Why Data Interoperability Challenges Are Holding Back Your Insights – And What to Do About It
Every modern organization thinks it’s interoperable—until the data says otherwise. Your systems are technically connected. APIs are firing. Data is flowing. But when you zoom

