































Last Updated on July 3, 2026
When two companies merge, their customer databases merge in name only. The same customer often exists under different account IDs, spelled differently, and formatted according to two separate systems’ conventions. What results is an inflated customer count, duplicate outreach to the same buyer, revenue attribution that does not reconcile, and a Customer 360 view that never actually forms.
This guide covers how to identify, match, and resolve those duplicates. It walks through the process as both a one-time consolidation project immediately after close and an ongoing API-driven process that keeps the unified database clean as new records enter it.
Why Post-Merger Customer Deduplication Is Uniquely Difficult
Two merging companies rarely store customer data the same way, and four specific problems make the mismatch harder to fix than it looks on paper.
- Schema mismatch. Company A stores a first name and last name in separate fields. Company B stores the same information as one full name field. Matching logic has to parse and reconcile these structures before any comparison can happen.
- Source system bias. Each CRM was maintained under its own data entry standards, abbreviation habits, and address formatting conventions, so what looks like a small typo is often a consistent pattern unique to one system.
- No shared unique identifier. There is no common customer ID across the two systems, so exact matching fails almost entirely and the project depends on matching by name, address, email, and phone instead.
- Overlap uncertainty. Neither side knows the true percentage of shared customers until the match runs, which means resourcing and timeline estimates going into the project are often guesses.
The Business Cost of Getting It Wrong
Unresolved post-merger duplicates do not stay a data problem. They surface as business problems within the first reporting cycle after close.
Revenue miscounting happens first. Duplicate customer records inflate the ARR and customer count figures reported to the board and used to plan the rest of the integration. A number built on inflated counts leads every decision built on top of it astray.
Broken customer experience follows close behind. The same customer receives duplicate outreach, sees conflicting account information depending on which system a rep pulled from, or gets assigned to two separate sales reps who have no idea the other exists.
Compliance exposure is the sharpest risk in regulated industries. In financial services and healthcare, duplicate records create multiple consent states, gaps in KYC screening, and an audit trail that cannot account for every merge decision made along the way. Regulators do not accept “the system was still being consolidated” as an answer during an audit.
The Four-Phase Post-Merger Deduplication Process
Every credible post-merger deduplication project follows the same four phases, whether the underlying tool is custom built or off the shelf.

Phase 1 Profile and Inventory
Before any matching begins, both source systems need a full audit. This means mapping every field, understanding what data type and format each field holds, and scoring how complete each dataset actually is. Skipping this step is the single most common reason match rates disappoint later. A team that understands what is actually sitting in each system before matching starts can predict where the hard cases will show up and plan for them instead of discovering them mid-project.
Phase 2 Schema Normalization
Once both systems are profiled, field formats need to be standardized before any comparison runs. Names get parsed into consistent components, addresses get standardized against postal reference data, and phone numbers and email addresses get normalized to a single format. Fuzzy matching run against unnormalized fields produces a lower accuracy rate than the same algorithm run against clean, standardized inputs, so this phase pays for itself directly in match quality.
Phase 3 Batch Matching and Duplicate Identification
With both datasets normalized, the full combined dataset runs through fuzzy and phonetic matching to generate a candidate list of likely duplicates, each with a confidence score attached. Survivorship rules then apply to each matched cluster to determine which record wins on a field by field basis. This phase is where most of the technical decisions in the project get made, and where an explainable, rules-based matching engine earns its keep over a black box model that cannot show its work.
Phase 4 Golden Record Output and System of Record Update
The resolved master record gets written back to the target system, and superseded duplicates get flagged or archived rather than deleted outright, preserving the audit trail. This is also the point where teams typically move from a one-time batch job to an API-based integration that catches duplicates as new records enter the newly unified system, so the clean state achieved in Phase 3 does not degrade within a few months.
Choosing Between Batch and API Deduplication After a Merger
Most post-merger deduplication projects start with a batch job, the Phase 3 work described above, to clean the full historical combined dataset in one pass. Once that initial consolidation is complete, an API integration takes over to catch and prevent duplicates as new records enter the unified system going forward. The two approaches are not competing options. They are sequential stages of the same project.
DataMatch Enterprise handles the batch consolidation phase, processing the merged dataset in one run and applying the survivorship rules configured for the project. DataMatch Enterprise Server API then handles ongoing prevention once the initial cleanup is done, checking new and updated records against the master database in real time. For a closer look at when each approach makes sense on its own, see when to use API vs batch deduplication.
| Stage | Tool | What It Handles |
| Initial consolidation | DataMatch Enterprise (batch) | One-time cleanup of the full combined historical dataset |
| Ongoing prevention | DataMatch Enterprise Server API | Real-time duplicate checking as new records enter the unified system |
Survivorship Rules and Deciding Which Record Wins
When two records match, a survivorship rule decides which field values populate the resulting golden record. Four rule types come up most often in post-merger projects.
Source hierarchy gives records from the acquiring company’s CRM precedence by default, on the assumption that the acquiring system is the one staying in place long term.
Most complete compares populated fields on a per-field basis and keeps whichever record has more data filled in, regardless of which system it came from.
Most recent keeps whichever field value carries the latest update timestamp, useful for fields like phone number or job title that change over time.
Validated overrides unvalidated values with ones that have passed address verification or format validation, on the logic that a confirmed value beats an unconfirmed one no matter which system it originated in.
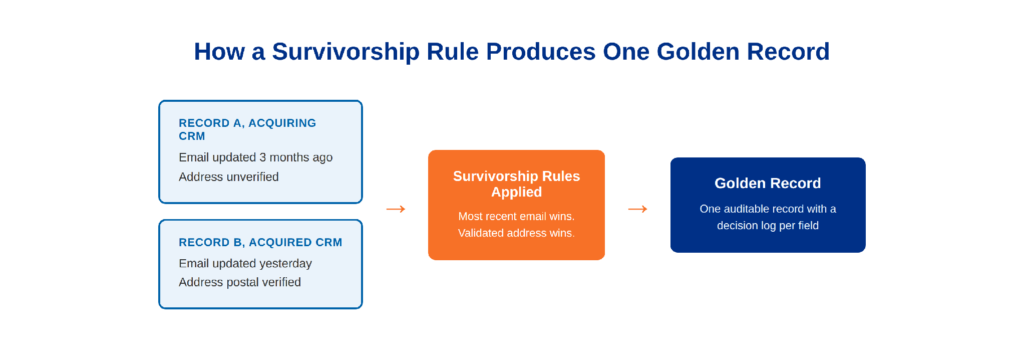
In DataMatch Enterprise, these rules are explicit and configurable per field, and every merge decision produces a decision log that can be reviewed later. That auditability matters as much as the match itself when a regulator or an internal audit team asks why a particular record ended up the way it did.
| Field | Rule Type Applied | Example Outcome |
| Email address | Most recent | The email with the latest activity timestamp is retained |
| Mailing address | Validated | The address that passed postal verification overrides the unverified one |
| Account owner | Source hierarchy | The acquiring company’s CRM value takes precedence |
| Phone number | Most complete | The record with both a primary and secondary number wins over one with only a primary number |
Industry-Specific Considerations
Financial Services and Banking
Post-merger KYC data consolidation carries regulatory weight that most other verticals do not face. Duplicate customer records create gaps in AML and sanctions screening, since a screening check run against one of two duplicate records is not actually a check against the full customer relationship. Regulators expect a single verified identity per customer after consolidation, and every merge decision needs an audit trail that can be produced on request.
Healthcare
Patient record deduplication across two EHR systems after a hospital system acquisition is its own discipline, often called MPI reconciliation. Matching has to work without transmitting protected health information unnecessarily, which shapes how the matching pipeline gets architected from the start rather than added as an afterthought. A missed match here does not just create a duplicate record, it risks a clinician working from an incomplete patient history.
B2B SaaS and Enterprise Software
Account and contact deduplication across two Salesforce orgs after an acquisition prevents the same buyer from receiving outreach from two different reps representing what is now the same company. Getting this right also fixes revenue attribution, since a duplicate account artificially splits a single customer’s spend across two records and understates account value in every report built afterward.
Common Mistakes in Post-Merger Deduplication Projects
Four mistakes show up repeatedly in post-merger deduplication projects, and all four are avoidable with the right sequencing.
- Starting matching before normalizing schema. This produces lower accuracy than the same matching algorithm run against clean data. Fuzzy matching on inconsistently formatted fields compounds every formatting inconsistency into a missed match.
- Using exact-match logic only. This guarantees missed duplicates. A record for “IBM Corp” and a record for “IBM Corporation” will not match on an exact string comparison, and post-merger datasets are full of exactly this kind of variation. Fuzzy and phonetic matching are required, not optional.
- Skipping a survivorship strategy upfront. This turns what should be an automated process into weeks of manual review, because no one agreed in advance which source system wins when values conflict.
- Treating deduplication as a one-time project. This guarantees the unified database re-contaminates within months. Without ongoing API-based prevention feeding off the golden record established in Phase 4, new duplicates enter the system just as fast as the old ones were cleaned out.
Frequently Asked Questions
How long does post-merger customer deduplication typically take?
Timeline depends heavily on dataset size and how disparate the two source systems are, but most projects run four to eight weeks from profiling through golden record output when using a purpose-built matching tool. Custom-coded or manual approaches routinely take several times longer and still produce lower match accuracy.
What is the typical overlap rate between two merged customer databases?
Overlap varies by industry and deal type, and it is rarely known with confidence before the match runs. Companies acquiring a direct competitor in the same market tend to see meaningfully higher overlap than companies acquiring into an adjacent market or geography.
Do we need to replace our CRM or MDM platform to deduplicate post-merger data?
No. Post-merger deduplication tools like DataMatch Enterprise sit alongside the existing CRM or MDM platform, matching and resolving records before writing the golden record back to whichever system stays in place after the merger. Replacing a platform is a separate decision from cleaning the data inside it.
How do survivorship rules work in a post-merger deduplication project?
A survivorship rule is a configured rule that decides which field value wins when two matched records conflict. Common rule types include source hierarchy, most complete, most recent, and validated, and they can be applied differently on a per-field basis within the same project.
Can DataMatch Enterprise handle two databases with different field structures?
Yes. Schema normalization runs before matching, parsing and standardizing fields like names, addresses, and phone numbers so that two differently structured systems can be compared accurately regardless of how each one originally stored the data.
What is the difference between a one-time deduplication job and ongoing API-based dedup after a merger?
A one-time deduplication job cleans the full historical dataset in a single batch run immediately after consolidation. Ongoing API-based deduplication checks new and updated records against the master database in real time as they enter the system, preventing the database from re-contaminating after the initial cleanup.
Consolidating customer data after a merger or acquisition is not a project most teams want to run twice. See how DataMatch Enterprise handles post-merger deduplication at scale, from initial batch consolidation through the survivorship rules that produce an auditable golden record. Request a demo
For teams that need ongoing duplicate prevention once the initial cleanup is done, the DataMatch Enterprise Server API extends the same matching logic into a real-time integration.

