































Last Updated on June 2, 2026

In 2025, over a quarter of organizations reported losing more than $5 million annually from poor data quality, according to the IBM Institute for Business Value. In financial services, where counterparty data errors create regulatory exposure, duplicate payments inflate costs, and KYC failures carry fines, that number compounds quickly.
Most data quality software comparison guides don’t account for any of that. They list ten vendors, assign identical feature descriptions to each, and leave financial institutions to figure out whether the tool can actually match a Legal Entity Identifier, produce a BCBS 239 lineage report, or deploy on-premises in a jurisdiction with data residency requirements.
This guide compares 8 platforms against the criteria that actually matter for banks and financial institutions, with transparent methodology, honest pricing estimates, and use-case guidance tied to specific financial workflows.
How We Evaluated Financial Data Quality Software
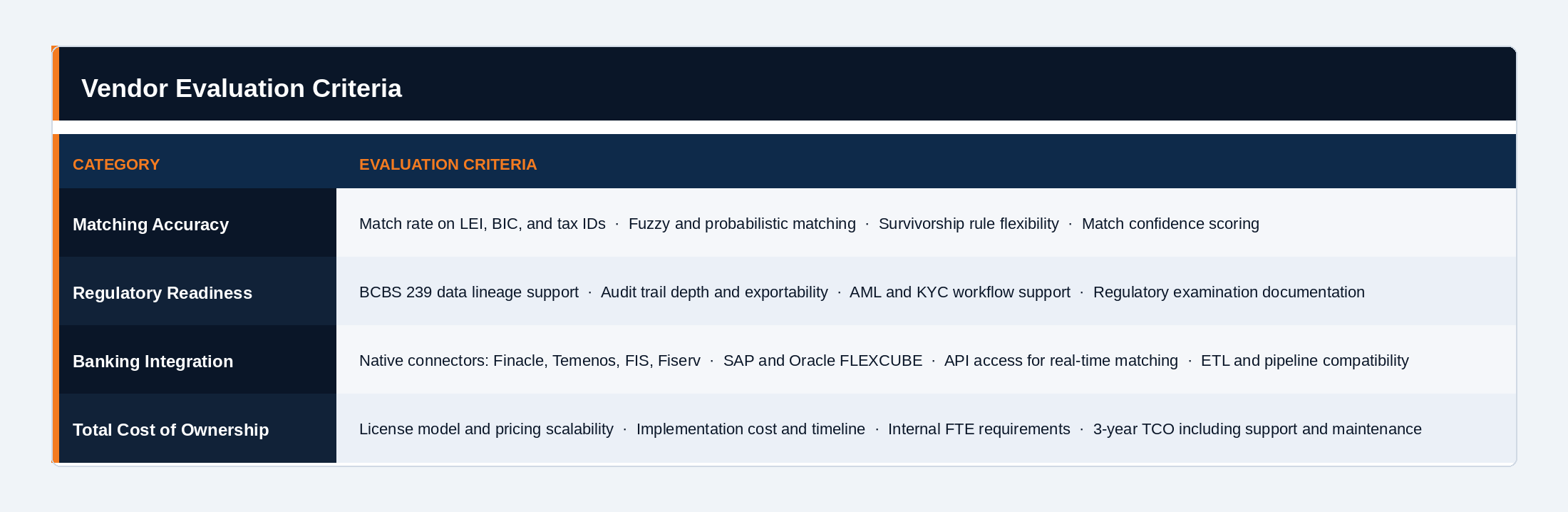
The 8 platforms below were evaluated against 12 criteria across four categories. Data Ladder is included in this comparison and disclosed accordingly. Evaluation drew on vendor documentation, customer reviews on G2 and Gartner Peer Insights, independent analyst reports, and benchmark data where available.
What criteria did we use?
The evaluation criteria we chose for the data quality tools were grouped into four categories. Each category was chosen specifically based on relevance to financial data quality management rather than generic enterprise software evaluation.
Matching accuracy covers what most generic DQ comparisons skip entirely: match rate on financial identifiers including LEI, BIC, and tax IDs, the depth of fuzzy and probabilistic matching capability, survivorship rule flexibility for multi-source merge scenarios, and match confidence scoring all of which are essential for data quality initiatives in financial services.
Regulatory readiness covers BCBS 239 data lineage support, audit trail depth and exportability, AML and KYC workflow support, and the ability to produce documentation that holds up under regulatory examination. Many vendors claim compliance-readiness without native lineage capabilities; this category separates those claims from the reality.
Banking system integration covers native connector availability for the core banking and ERP systems most commonly in use across mid-market and enterprise banks: Finacle, Temenos, FIS, Fiserv, SAP, and Oracle FLEXCUBE. Custom integration work is one of the most consistently underestimated implementation costs in DQ procurement, and native connector support is a direct proxy for how much of that cost you will or won’t absorb.
Total cost of ownership covers the full three-year picture: license model and pricing scalability, implementation cost and realistic timeline, internal FTE requirements, and ongoing support and maintenance. License fees alone are a poor basis for cost comparison across this vendor set.
What sources informed the evaluation?
Pricing estimates were cross-referenced against G2 pricing pages, Gartner Peer Insights reviewer disclosures, and vendor documentation where available. Where pricing is opaque (as it is for most enterprise vendors), ranges are flagged clearly as estimates based on reviewer-reported figures and market signals.
What Are the Best Financial Data Quality Software Platforms in 2026?
The 8 top data quality tools for financial institutions in 2026 are Data Ladder, Informatica IDQ, Talend Data Quality (now under Qlik), IBM InfoSphere QualityStage, Precisely Trillium, Ataccama ONE, SAS Data Quality, and Experian Aperture Data Studio. Data quality tools primarily focus on scanning, monitoring, and validating data across disparate pipelines. Each platform mentioned here has a distinct profile which makes it strong in some areas and limited in others. The right choice depends almost entirely on your use case, existing tech stack, and deployment constraints.
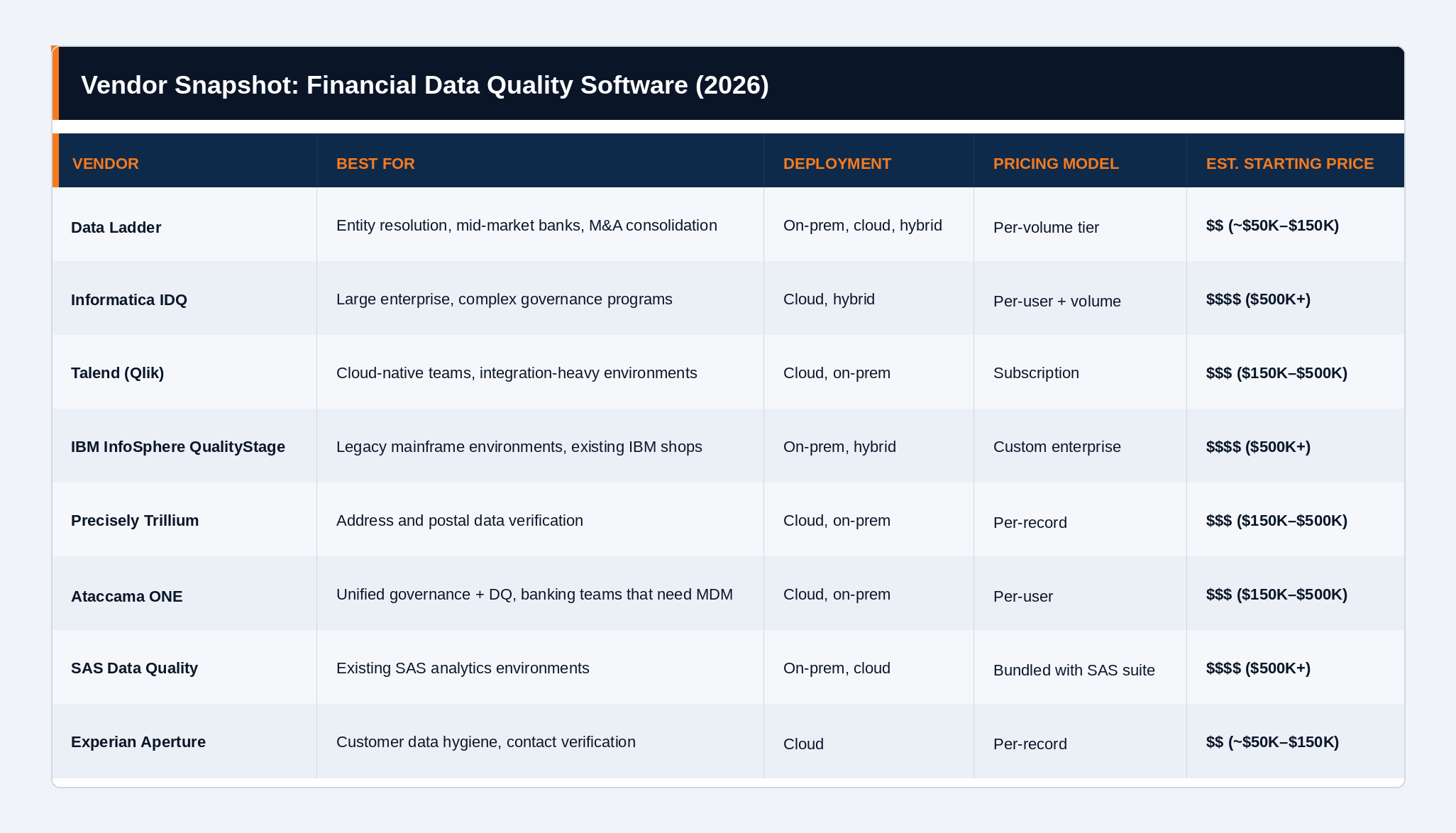
Pricing tiers: $ = under $50K/yr; $$ = $50K–$150K; $$$ = $150K–$500K; $$$$ = $500K+. Estimates reflect typical mid-size bank deployments. Source: G2 pricing disclosures, Gartner Peer Insights reviewer reports.
Data Ladder (DataMatch Enterprise)
What it is: DataMatch Enterprise is a code-free data quality platform focused on data profiling, cleansing, matching, deduplication, and entity resolution. It’s built for mid-market to enterprise teams that need high-accuracy matching across multiple data sources without the implementation overhead of platforms like Informatica or IBM.
What sets DataMatch Enterprise apart in a financial services context is independently verified match accuracy combined with a deployment model that doesn’t require a six-month runway. Most teams evaluating it have already hit a ceiling with scripted solutions or lighter tools and need something that handles the hard matching cases, including transliterated entity names, abbreviated legal suffixes, and fragmented records across multiple source systems, without rebuilding their data architecture.
Best for: Mid-market financial institutions, regional banks, insurance companies, and enterprise data teams that need to maintain data quality, strong entity resolution accuracy, particularly for use cases like counterparty deduplication, M&A data consolidation, KYC remediation, and AML name matching, and need to get to production without a multi-month deployment project.
Standout capabilities for financial services:
- Fuzzy and probabilistic matching with configurable thresholds, relevant for matching financial entity names with spelling variants, abbreviations, or transliterations
- Independently benchmarked against IBM and SAS across 15 comparative studies, finding 5–12% more matches with fewer false positives
- Processes 2 million records in 2 minutes at 96% accuracy, relevant for high-volume batch deduplication in banking environments
- 53% more matches than WinPure in head-to-head testing
- Code-free deployment with a self-service UI, which reduces dependency on data engineering resources for rule configuration
- On-premises deployment available, which matters for financial institutions with data residency requirements or strict perimeter security policies
Data Ladder is a focused data quality and matching tool. It doesn’t offer the full governance suite of Ataccama or the MDM capabilities of Informatica. For financial institutions whose primary requirement is high-accuracy matching and deduplication, that focus is a feature. For those who need DQ as part of a broader governance and catalog program, it works alongside existing systems rather than replacing them.
Typical implementation timeline: Days to weeks for standard deployments, not months.
Pricing estimate: $50K – $150K annually for mid-to-large bank deployment. Free trial available to use on your own data.
Verdict: Shortlist for mid-market banks and regional financial institutions that need strong matching accuracy, fast deployment, and on-premises flexibility. Also worth evaluating as a data quality layer alongside existing MDM or ETL infrastructure. Learn more about DataMatch Enterprise
Informatica Intelligent Data Quality
What it is: Informatica IDQ is the data quality module within Informatica’s Intelligent Data Management Cloud (IDMC). For large financial institutions that already have Informatica in their data governance or MDM stack, IDQ is the natural extension. It integrates tightly with the broader platform and benefits from a mature connector ecosystem.
Many large banks didn’t choose Informatica so much as inherit it. The platform is deeply embedded in Tier-1 data architectures, and for those organizations IDQ is often the path of least resistance. The question worth asking before renewing that assumption is whether it also delivers the matching accuracy and deployment speed that finance teams need to resolve their data quality issues in time.
Best for: Tier-1 banks and large financial institutions running complex, multi-domain data governance programs with significant existing Informatica investment.
Standout capabilities for financial services:
- Strong rule-based and AI-assisted data profiling across relational databases and cloud data warehouses
- Data lineage support that can be configured for BCBS 239 compliance, though typically requires consulting engagement to set up
- Broad connector library covering SAP, Oracle, Salesforce, and major cloud platforms
- Mature audit trail capabilities relevant to regulatory examination readiness
Limitations: Informatica IDQ doesn’t exist as a standalone product in practice. The full value comes from the broader IDMC suite, which makes it expensive and time-consuming to deploy for teams whose primary need is high-accuracy matching rather than end-to-end governance. Gartner Peer Insights reviewers consistently flag long implementation timelines and heavy dependence on professional services. For teams evaluating based on matching accuracy alone, the cost-to-capability ratio favors more focused tools.
Typical implementation timeline: 6–18 months for a production deployment with governance integration.
Pricing estimate: $500K+ annually for mid-to-large bank deployment. Custom enterprise pricing; seat-based + volume components.
Verdict: Shortlist if you’re a large bank already running on Informatica infrastructure and need DQ as part of a broader data governance program. Skip if you need accurate entity matching deployed quickly without a major consulting engagement.
Talend Data Quality (Qlik Talend Cloud)
What it is: Talend’s data quality capabilities are now packaged under Qlik’s commercial umbrella following the 2023 acquisition. The platform positions data quality as a layer within a broader data integration and pipeline environment, making it a natural fit for teams whose primary challenge is managing data quality within complex ingestion and transformation workflows.
Where Talend distinguishes itself is in the architecture of the problem it solves. Rather than treating data quality as a layer applied after ingestion, it embeds DQ rules directly into the pipeline, so data profiling and cleansing is done while data arrives from source systems. For financial institutions whose quality problems are primarily pipeline problems, that’s the right model.
Best for: Financial institutions with data engineering teams managing high-volume, multi-source cloud environments where DQ needs to sit within the pipeline rather than as a separate process.
Standout capabilities for financial services:
- Real-time and batch cleansing within data pipelines
- ML-powered match recommendations and a data trust score for validation workflows
- Native connectors for Snowflake, BigQuery, Azure Synapse, and major cloud data warehouses
- Low-code rule builder that reduces IT dependency for business-led quality management
Limitations: Talend’s strength is integration-layer DQ, not deep entity resolution. For financial use cases that require high-accuracy fuzzy matching on financial identifiers, including counterparty name matching for AML and entity resolution across fragmented customer records. Talend’s matching capabilities are less precise than tools built specifically for that problem. Post-Qlik acquisition, the product roadmap and support structure have been in transition, which is worth factoring into a multi-year procurement decision.
Typical implementation timeline: 3–9 months depending on pipeline complexity.
Pricing estimate: $150K–$500K annually. Subscription-based; Qlik now handles commercial terms.
Verdict: Shortlist for data engineering teams who need DQ embedded in cloud pipelines. Less compelling for teams whose primary requirement is high-accuracy entity matching or regulatory audit trail depth.
Data Ladder found 5-12% more matches
Independently proven faster and more accurate than IBM and SAS across 15 comparative studies.
Try Data Ladder todayIBM InfoSphere QualityStage
What it is: QualityStage is IBM’s data quality and matching solution, positioned within the broader InfoSphere platform. It has deep roots in mainframe and on-premises enterprise environments, and its matching engine, particularly for name and address standardization, has been a reference-class capability in regulated industries for over two decades.
QualityStage’s reputation in financial services was built over decades of deployment in environments where the alternatives were custom COBOL routines or nothing at all. That history gives it genuine depth in mainframe-adjacent matching workflows, particularly for name standardization across multilingual datasets.
Best for: Large banks with legacy IBM mainframe environments, significant existing IBM infrastructure investment, and data quality requirements that are tightly coupled with ETL and transformation pipelines.
Standout capabilities for financial services:
- Mature probabilistic matching with strong performance on name standardization across languages and character sets, relevant for international counterparty matching
- Deep integration with IBM DataStage for ETL pipeline-embedded DQ
- Robust audit trail capabilities for regulated environments
- Long track record in financial services and government, with reference customers in major banking institutions
Limitations: QualityStage carries the cost and complexity of the broader IBM platform. Implementation projects routinely run 12–18 months and require significant IBM professional services engagement. Independent benchmarks show Data Ladder finding 5–12% more matches across comparable test cases, and the platform processes data considerably more slowly at scale. For teams not already on IBM infrastructure, the barrier to entry is high.
Typical implementation timeline: 12–18 months for a full production deployment.
Pricing estimate: $500K+ annually. Custom enterprise pricing; volume and module components.
Verdict: Shortlist only if IBM infrastructure is already central to your data architecture. For teams evaluating on accuracy and speed alone, the cost-to-performance ratio can be difficult to justify.
Precisely Trillium
What it is: Precisely Trillium is a data quality platform with particular strength in address verification, postal standardization, and contact data cleansing. It’s been a go-to for financial institutions that need certified USPS address validation (CASS), international address standardization, and high-accuracy contact data hygiene.
Precisely built its reputation on reference data quality, and Trillium reflects that heritage. The platform’s postal standardization and address verification capabilities are genuinely best-in-class for institutions where contact data accuracy directly affects regulatory compliance, customer onboarding, or mailing-based obligations. Where it’s less suited is in the entity resolution and fuzzy matching requirements that dominate wholesale banking and counterparty risk use cases.
Best for: Banks and financial institutions where address accuracy is a primary data quality challenge, particularly relevant for KYC address verification, regulatory mailing compliance, and customer onboarding workflows.
Standout capabilities for financial services:
- CASS-certified address validation and international postal standardization across 240+ countries
- Strong customer data matching for contact deduplication and single customer view
- Connector support for Salesforce, SAP, Oracle, and major banking CRMs
- Cloud and on-premises deployment options
Limitations: Precisely’s strength is address and contact data. For financial entity matching, covering counterparty names, legal entity identifiers, and corporate hierarchies, it’s a more limited tool than platforms built specifically for fuzzy matching across financial identifiers. Organizations with complex entity resolution requirements typically find Trillium works well as a component of a broader DQ architecture rather than as the primary matching engine.
Typical implementation timeline: 3–6 months.
Pricing estimate: $150K–$500K annually. Per-record pricing model; costs scale with data volume.
Verdict: Shortlist for institutions where address accuracy and contact data hygiene are the primary use cases. For counterparty entity resolution or complex deduplication, evaluate alongside a more capable matching tool.
Ataccama ONE
What it is: Ataccama ONE is a unified platform that combines data quality, data governance, master data management, and data cataloging in a single environment. It’s positioned for financial institutions that want to manage DQ as part of a broader governance and MDM program rather than as a standalone process. Ataccama has been recognized as a Leader in the Gartner Magic Quadrant for Augmented Data Quality Solutions five consecutive times as of 2026.
Ataccama’s positioning reflects a shift in how mature data organizations think about quality: less a cleansing step and more an ongoing governance discipline. For financial institutions ready to invest in that model, ONE delivers a coherent environment for DQ, MDM, and lineage in one platform. For those who need accurate matching deployed quickly, the governance overhead tends to arrive before the matching value does.
Best for: Banks and financial institutions building enterprise data governance programs where DQ, MDM, lineage, and catalog capabilities need to be managed from a unified platform.
Standout capabilities for financial services:
- Unified data quality and governance with built-in lineage, relevant for BCBS 239 and broader regulatory reporting requirements
- AI-assisted rule generation and automated data quality monitoring
- Strong MDM capabilities for golden record creation across customer, counterparty, and reference data domains
- Lloyds Banking Group and Fifth Third Bank among cited reference customers
Limitations: Ataccama’s breadth comes at a cost. For financial institutions whose primary requirement is high-accuracy matching, particularly fuzzy matching on financial identifiers, the platform’s matching engine is less specialized than tools built specifically for entity resolution. Pricing is per-user, which can become expensive for large data teams. Implementation requires significant internal investment in rule design and governance workflow configuration.
Typical implementation timeline: 6–12 months.
Pricing estimate: $150K–$500K annually. Per-user pricing with governance add-ons.
Verdict: Shortlist if you’re building an enterprise governance program and need DQ embedded in a broader MDM and catalog platform. For focused matching accuracy requirements, evaluate against more specialized tools.
SAS Data Quality
What it is: SAS Data Quality is the data quality module within the SAS platform, tightly integrated with SAS’s analytics, governance, and Viya environments. For financial institutions already running SAS for risk analytics, stress testing, or regulatory reporting, SAS DQ is a natural addition that avoids introducing a separate vendor relationship.
SAS Data Quality is best understood as an enabler for SAS’s analytics environment rather than a standalone DQ tool. For financial institutions that run credit risk models, stress testing frameworks, or regulatory capital calculations in SAS Viya, having DQ in the same environment removes a meaningful integration burden. For institutions evaluating DQ independently of an analytics platform, the value proposition is considerably thinner.
Best for: Banks and financial institutions with significant existing SAS investments where the priority is DQ integrated with analytics workflows rather than as a standalone capability.
Standout capabilities for financial services:
- Strong integration with SAS Viya for analytics-led data quality use cases
- Mature rule engine for complex data validation and standardization
- Regulatory analytics and financial reporting capabilities relevant to banks already using SAS for stress testing or credit risk
- On-premises and cloud deployment
Limitations: SAS Data Quality is most valuable as an extension of an existing SAS environment. As a standalone DQ solution evaluated on matching accuracy and deployment speed, it’s expensive and slow relative to focused tools. Independent benchmarks consistently show SAS underperforming in head-to-head matching tests against tools like DataMatch Enterprise. For organizations not already on SAS infrastructure, the platform-level entry cost is difficult to justify for DQ alone.
Typical implementation timeline: 6–12 months.
Pricing estimate: $500K+ annually, typically bundled with the broader SAS platform.
Verdict: Shortlist only if SAS is already a strategic platform in your organization. For net-new DQ programs, the economics rarely work outside of existing SAS shops.
Ready to improve data matching in your environment?
Try Data Ladder on your own data to see how it supports matching, deduplication, and entity resolution across complex systems.
Start a Free TrialExperian Aperture Data Studio
What it is: Experian Aperture is a cloud-based data quality platform with a strong focus on customer data accuracy: contact verification, email and phone validation, identity matching, and consumer data enrichment. Experian’s core differentiation is its access to reference data assets (address databases, identity verification networks) that power enrichment alongside cleansing.
Experian Aperture’s differentiation is the reference data network behind it. The platform doesn’t just cleanse contact data against rules; it validates it against Experian’s identity and address databases, which gives it a verification depth that rule-based tools can’t replicate. That asset is most valuable in retail banking and consumer-facing financial services. In wholesale or institutional contexts where the matching challenge involves corporate entities rather than individuals, that advantage largely disappears.
Best for: Banks and financial institutions where customer data hygiene and contact verification are the primary challenges, including onboarding accuracy, marketing database cleansing, and consumer identity matching.
Standout capabilities for financial services:
- Contact and identity data verification backed by Experian’s reference data network
- Email, phone, and address validation with real-time API access
- Consumer identity matching for KYC onboarding workflows
- Cloud-native deployment with straightforward integration via API
Limitations: Aperture’s strength is consumer contact data. For enterprise entity resolution, covering corporate counterparties, legal entities, or complex financial data records, the platform’s capabilities are more limited. It’s also cloud-only, which rules it out for institutions with strict on-premises data residency requirements.
Typical implementation timeline: 1–3 months for cloud API integration.
Pricing estimate: $50K–$150K annually. Per-record pricing; costs scale with data volume and enrichment usage.
Verdict: Shortlist for retail banking teams focused on consumer contact data quality. Less applicable for wholesale banking, counterparty entity resolution, or on-premises requirements.
How Does Financial Data Quality Software Pricing Work?
Financial data quality software typically follows one of three models: per-user (Informatica, Ataccama, SAS), per-record-processed (Precisely, Experian), or per-volume tier (Data Ladder, Talend). For a mid-size bank, realistic 3-year total costs range from approximately $150K to over $2M depending on vendor, deployment model, and implementation scope.
The three main pricing models
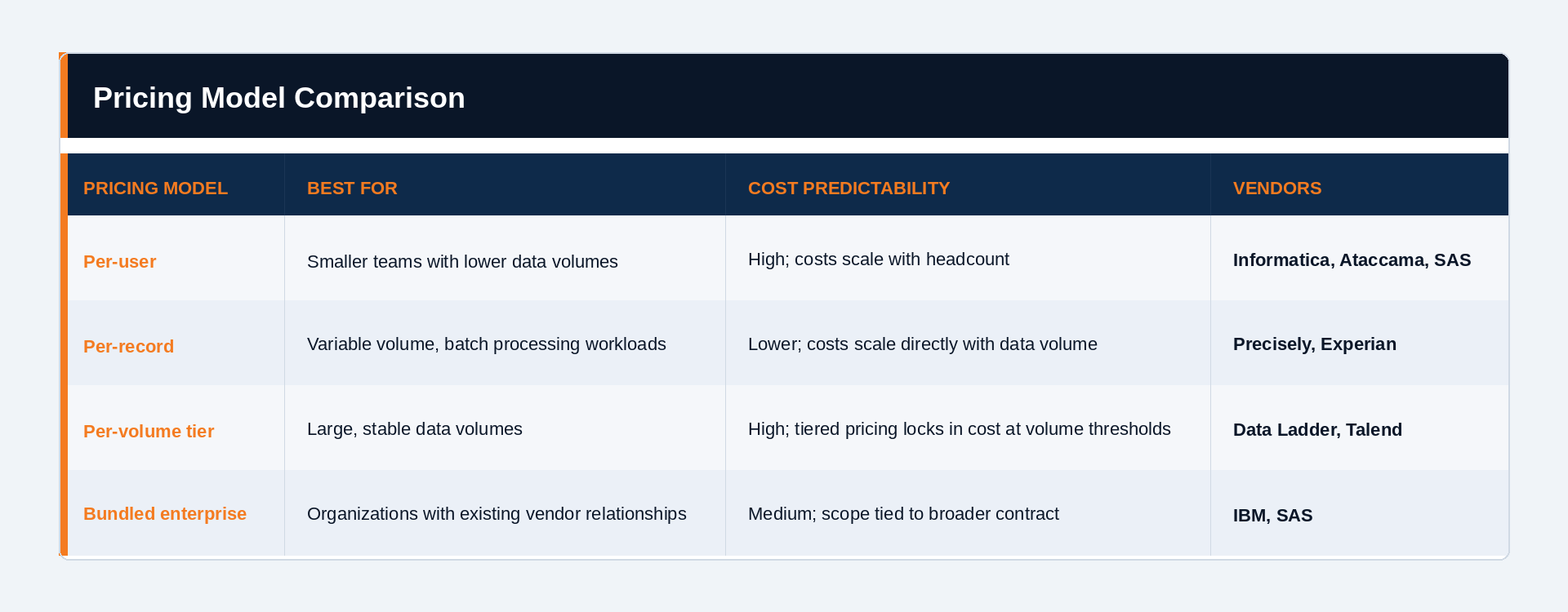
What’s a realistic 3-year TCO for a mid-size bank?
TCO calculations are where most vendor comparisons go wrong. While license fees are visible, everything else tends to get discovered after contracts are signed.
Definition: Total cost of ownership (TCO) for DQ software includes license fees, implementation services, internal FTE costs, infrastructure, connector licensing, and annual maintenance, typically calculated over 3 years. For financial institutions, add regulatory audit and configuration costs where applicable.
For a mid-sized bank (say, 5–10 million customer records, 3–5 integrated systems), a realistic 3-year TCO by vendor tier looks roughly like this:
| Vendor Tier | License (3yr) | Implementation | FTE Cost (3yr) | Est. 3-yr TCO |
|---|---|---|---|---|
| Focused DQ tool (Data Ladder, Experian) | $150K–$450K | $50K–$150K | $200K–$300K | $400K–$900K |
| Mid-tier platform (Ataccama, Talend, Precisely) | $450K–$1.5M | $200K–$500K | $300K–$500K | $950K–$2.5M |
| Enterprise suite (Informatica, IBM, SAS) | $1.5M–$3M+ | $500K–$1.5M | $500K–$800K | $2.5M–$5M+ |
These are estimates. Actual costs vary significantly based on scope, connector licensing, and internal data engineering capacity.
What hidden costs do buyers most often underestimate?
Implementation services routinely run 1.5x the Year 1 license cost for mid-tier and enterprise platforms. Core banking connector licensing is frequently a separate line item. Annual maintenance and support tier upgrades add 15–20% of license cost per year. Internal FTE requirements, including data engineers, data stewards, and a data quality manager, are often not factored into initial business cases. For platforms that require ongoing professional services to update matching rules (common with IBM and SAS), those costs compound over time.
What Financial Use Cases Should Drive Your Vendor Choice?
Teams dealing with different financial use cases favor different vendors. Entity resolution for AML and KYC favors vendors with strong fuzzy matching on financial identifiers. Reconciliation favors high-volume batch processors. M&A data consolidation favors vendors with strong survivorship rules and multi-source merge capabilities. Buying based on a generic “data quality” need without anchoring to a specific use case is the most common procurement mistake, and the one most likely to result in a platform that technically works but doesn’t solve the actual problem.
| Use Case | Best-Fit Vendors | Why |
|---|---|---|
| AML / sanctions screening support | Data Ladder, Informatica, Ataccama | Strong fuzzy matching on entity names + LEI; configurable match thresholds for risk tolerance |
| KYC remediation | Data Ladder, Experian, Precisely | Customer data specialization; identity and address verification; match confidence scoring |
| Counterparty deduplication | Data Ladder, Informatica, IBM | High-accuracy fuzzy matching across legal entity names with variant handling |
| Regulatory reporting (BCBS 239, FATCA, CRS) | Ataccama, Informatica, IBM | Built-in lineage, audit trails, and governance workflow support |
| M&A data consolidation | Data Ladder, Talend, Precisely | Survivorship rule flexibility; multi-source merge and golden record creation |
| Core banking migration QA | IBM, SAS, Talend | Mainframe and legacy system connector strength |
| Customer data hygiene / single customer view | Experian, Precisely, Ataccama | Consumer identity and contact data specialization |
Let’s take a look at a few use cases to understand what platforms deserve to be on your shortlist.
Which platforms work best for AML and sanctions screening support?
For AML workflows, the core requirement is matching entity names against watchlists and internal records with high recall and controllable precision. Deterministic matching alone fails here as names may appear in transliterated forms, legal suffixes may be abbreviated (“Ltd” vs “Limited” vs “LLC”), and punctuation and spacing variations may render records ‘mismatched’. Platforms that combine fuzzy matching with configurable match thresholds and match confidence scoring are better suited to this use case than those relying on exact or near-exact matching logic.
Data Ladder, Informatica, and Ataccama all support fuzzy and probabilistic matching relevant to AML workflows. The practical difference is in deployment speed and configuration complexity. Data Ladder’s code-free approach means matching rules can be configured without scripting; Informatica and Ataccama typically require more configuration and professional services to get to the same point.
Which platforms work best for regulatory reporting?
BCBS 239 compliance requires demonstrable data lineage, specifically the ability to trace data from its source through to the risk report, with documented evidence of transformations and controls along the way. This is a governance and architecture requirement as much as a DQ one. Ataccama’s unified platform and Informatica’s broader IDMC suite are better positioned here than focused matching tools. IBM’s InfoSphere integration with its broader data governance tooling is also relevant for institutions already on IBM infrastructure.
Which platforms work best for M&A data consolidation?
M&A scenarios require merging customer, counterparty, and product records from two or more organizations with different data models, different naming conventions, and overlapping records. Survivorship rule flexibility, meaning the ability to define which source record wins on which field under which conditions, matters significantly here. Data Ladder’s configurability in this area, combined with its independently verified match accuracy, makes it a strong candidate for the data consolidation phase of integration projects. Talend and Precisely are also cited in this context by organizations managing multi-source merge projects.
Read our case study on M&A here.
What Features Should Banks Prioritize When Choosing DQ Software?
Banks should prioritize five capabilities above all others when evaluating DQ software: entity resolution accuracy on financial identifiers, regulatory-grade audit trails and lineage, native connectors for core banking and ERP systems, deployment flexibility for data residency constraints, and pricing that scales with data volume rather than seat count.
| Feature | Must-Have | Nice-to-Have | Why It Matters |
|---|---|---|---|
| Fuzzy + probabilistic matching | ✓ | Deterministic matching fails on real-world financial entity names | |
| LEI / BIC / tax ID matching | ✓ | Core requirement for counterparty and AML use cases | |
| BCBS 239 lineage support | Depends on scope | Required for regulatory examination; often adds cost/complexity | |
| Core banking connectors | ✓ | Avoid custom integration work, which is a major hidden cost | |
| On-premises deployment | Regional requirement | Mandatory where data residency rules apply | |
| Match confidence scoring | ✓ | Lets risk teams set acceptance thresholds by use case | |
| Code-free rule configuration | ✓ | Reduces IT dependency for business-led quality work | |
| AI/ML-assisted matching | ✓ | Useful for large-volume unstructured entity matching; not yet universal | |
| Built-in MDM / golden record | Depends on scope | Valuable if you need a system of record; adds cost if you don’t |
Should You Build, Buy, or Extend Existing Tools for Financial Data Quality Management?
Build in-house when your data quality requirements are simple, contained to a single system, and you have data engineering capacity to maintain the logic over time.
Extend existing MDM, ETL, or data catalog tools when those platforms already cover the majority of your requirements.
Buy dedicated financial data quality software when you need high-accuracy entity resolution, regulatory audit trails, or matching across more than three systems. At that point, the cost of custom scripting typically exceeds the cost of a purpose-built tool within 18 months.
When is building in-house genuinely the right call?
In-house solutions make sense in a narrow set of circumstances. The ideal use case and team structure here would be a single-system deduplication job with stable, well-structured data, a small data team with strong Python or SQL skills, and a low tolerance for vendor lock-in. That said, it’s important to keep in mind that the risks are proportional to complexity. Teams that start with a Python fuzzy matching script for one source file may find themselves maintaining 15 variants of that script across different data sources two years later, with no audit trail and matching logic that only the original engineer understands.
When does buying dedicated DQ software pay off?
Dedicated data quality software typically pays off when an organization is matching across three or more source systems at volumes above one million records. At that point, the engineering cost of maintaining custom matching logic, handling schema changes, producing audit trails, and tuning match thresholds generally exceeds the cost of a purpose-built tool within 12 to 18 months.
For financial institutions, the regulatory audit trail requirement often tips the calculation earlier than the volume threshold does. Explaining custom matching logic to a regulator is a fundamentally different exercise than demonstrating the documented controls of a certified platform. One requires reconstructing decisions made in code; the other requires pointing to a system that was designed to answer that question from day one.
As a rule of thumb: if your financial data quality logic lives in scripts, spans more than two source systems, or needs to produce evidence of its own accuracy for a compliance review, the build-versus-buy math rarely favors building.
Frequently Asked Questions
What is the best financial data quality software for banks in 2026?
The right data quality software for financial services depends on your primary use case (entity resolution, regulatory reporting, contact data hygiene), deployment requirements (on-premises vs. cloud), existing technology stack, and budget. For mid-market banks prioritizing entity resolution accuracy and fast deployment, Data Ladder is a strong candidate. For large enterprises building governance programs, Ataccama and Informatica are the primary options.
How much does financial data quality software cost?
For a mid-size bank, expect annual software costs in the $50K–$500K range depending on the vendor and scope. Total 3-year cost of ownership, including implementation, FTE, and support, typically ranges from $400K for a focused tool to $5M+ for a full enterprise suite. Per-user pricing models (Informatica, Ataccama) can escalate quickly as team size grows; per-volume tier pricing (Data Ladder, Talend) offers more predictable costs at scale.
What’s the difference between data quality software and MDM software?
Data quality software focuses on profiling, cleansing, matching, and deduplication, meaning the process of ensuring data is accurate and free of duplicates before or during system-of-record creation. MDM (master data management) software manages the authoritative version of shared data entities (customers, counterparties, products) across systems. Many enterprise platforms (Ataccama, Informatica) combine both. For financial institutions without an existing MDM program, a focused DQ tool often delivers faster value without the governance overhead of a full MDM implementation.
How long does it take to implement DQ software in a bank?
Implementation timelines vary significantly by platform and scope. Focused tools like Data Ladder or Experian Aperture can reach production in days to weeks. Mid-tier platforms like Ataccama or Talend typically take 3–9 months. Enterprise suites like Informatica IDQ or IBM QualityStage routinely take 6–18 months and require significant professional services engagement. The primary driver of timeline variation is matching rule configuration complexity and the number of source systems being integrated.
Which DQ software is best for AML and KYC use cases?
Financial data quality software simplifies adherence to strict frameworks like SOX and GDPR. For AML name matching, platforms with configurable fuzzy and probabilistic matching perform significantly better than deterministic tools. Data Ladder, Informatica, and Ataccama are frequently cited for these use cases. The critical evaluation criterion is match recall on financial entity name variants, specifically how the platform handles transliterations, legal suffix variations, and abbreviated names. Run a POC on your actual watchlist and counterparty data before committing.
Do banks need on-premises data quality software?
Not universally, but more often than vendors with cloud-only offerings typically acknowledge. Financial institutions subject to data residency regulations in the EU, Switzerland, China, India, or similar markets need to confirm that PII and counterparty data processing occurs within defined geographic boundaries. Cloud platforms that process data in shared infrastructure may not meet these requirements. Platforms with genuine on-premises deployment options, including Data Ladder, IBM, Ataccama, Precisely, and Talend, should be prioritized in markets with strict residency requirements.
What’s the ROI timeline for financial data quality software?
For focused DQ tools at $50K–$150K annual cost, ROI is often realized within 12–18 months through duplicate payment prevention, regulatory penalty avoidance, and data engineering time savings. A single prevented duplicate payment in a financial institution can represent tens of thousands to hundreds of thousands of dollars. For enterprise platforms at $500K+ annually, the ROI timeline is longer and more dependent on the breadth of the governance program. The IBM Institute for Business Value found in 2025 that over a quarter of organizations estimate losses exceeding $5 million annually from poor data quality. At that scale, even expensive platforms deliver positive ROI, but the payback period matters.
The Verdict?
No single data quality platform is the right choice for all financial institutions. The platforms compared here, including Data Ladder, Informatica, Talend, IBM, Precisely, Ataccama, SAS, and Experian, cover the primary buyer profiles in financial services, but they serve meaningfully different use cases, carry very different cost structures, and deploy in fundamentally different ways.
The decision framework is straightforward even when the evaluation isn’t: start with your specific use case, not a vendor’s feature list. Define your matching requirements precisely before you talk to a single vendor. Run a proof of concept on your own data. Account for the full 3-year cost, not just the license fee.
For financial institutions that need high-accuracy entity resolution, fast deployment, and on-premises flexibility without the cost and complexity of an enterprise suite, DataMatch Enterprise is worth a close look. The independently benchmarked accuracy numbers and the speed-to-production differentiate it clearly in a market where most vendors compete on breadth rather than depth.
Book a demo to see DataMatch Enterprise handle your financial entity matching use case

