







































DME allows you to prepare your data before deduping it, which involves advanced data profiling , cleansing, and standardization. With DME, you can execute the necessary steps to ensure deduplication accuracy, such as pattern recognition, word replacement, letter case transformation, and address standardization.
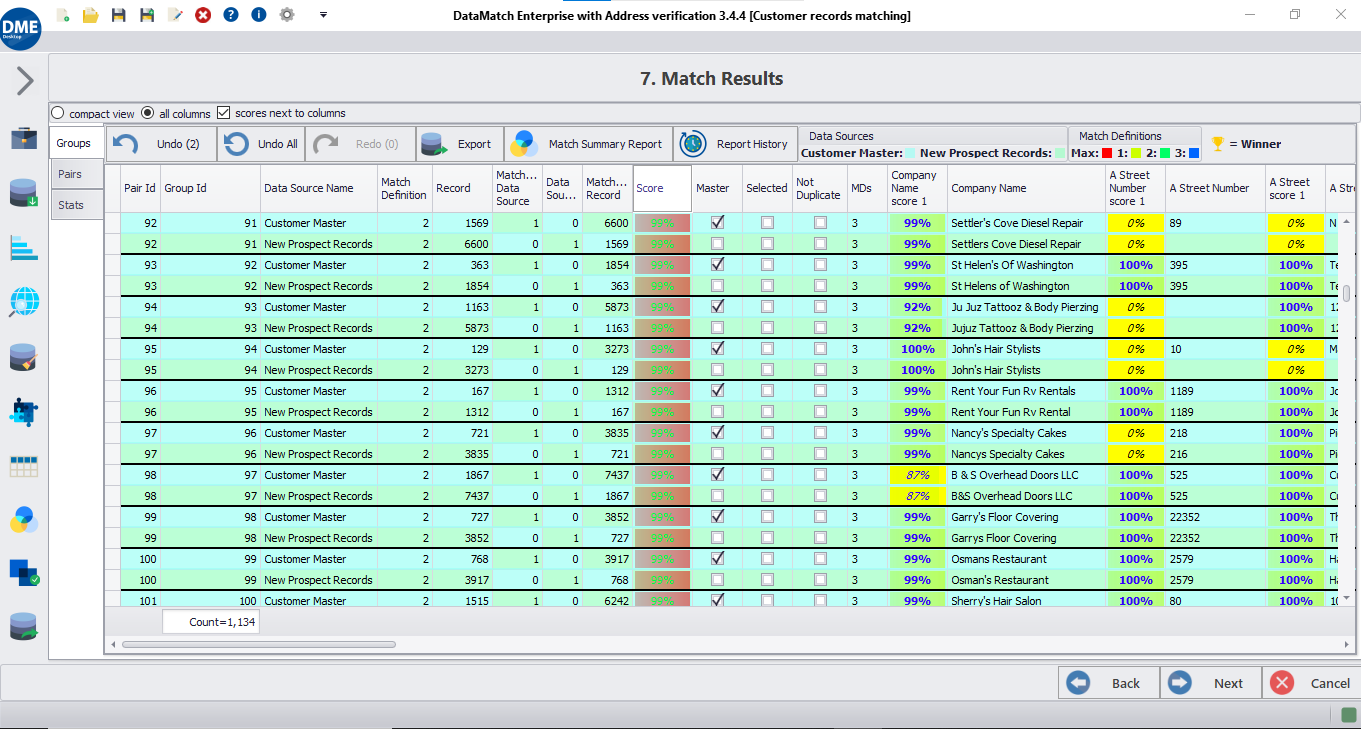
DME leverages advanced field and record matching techniques that consider misspellings, human typographical errors, and conventional variations in data values. DME can assess similarity between records right down to the character level. Moreover, advanced fuzzy matching techniques are also used to compare words and long sentences.

Data analysts

Business users

IT Professionals

Novice users


Merging Data from Multiple Sources – Challenges and Solutions

Best Financial Data Quality Software: Features, Pricing, and Use Cases (2026)
Last Updated on June 2, 2026 In 2025, over a quarter of organizations reported losing more than $5 million annually from poor data quality, according
How to Build a Financial Data Quality Management Program (2026 Guide)
Last Updated on May 25, 2026 Financial data quality management is the set of processes, ownership structures, and controls that finance and IT teams use
Best Financial Data Quality Software: Features, Pricing, and Use Cases (2026)
Last Updated on June 2, 2026 In 2025, over a quarter of organizations reported losing more than $5 million annually from poor data quality, according
How to Build a Financial Data Quality Management Program (2026 Guide)
Last Updated on May 25, 2026 Financial data quality management is the set of processes, ownership structures, and controls that finance and IT teams use
Master Data Cleansing: How to Get Results in Weeks, Not Months After Implementation
Last Updated on May 15, 2026 A few years ago, McKinsey’s Global Data Transformation Survey found that organizations spend an average of 30% of their
