































Last Updated on May 15, 2026
A few years ago, McKinsey’s Global Data Transformation Survey found that organizations spend an average of 30% of their total enterprise time on non-value-added tasks directly caused by poor data quality. Poor quality data undermines operational efficiency, decision making, and can lead to costly errors across business functions. Unclean data can hinder project success, making it critical to address data issues proactively. For this reason, regular monitoring and maintenance of data quality is necessary to ensure master data remains accurate and up to date.
Master data cleansing is an essential process for ensuring reliable data and operational efficiency. Accurate datasets dramatically reduce costly errors in marketing, logistics, and finance, contributing to revenue growth and cost savings.
In this guide, we’ll cover how to scope and execute master data cleansing, which tasks to run first, what can be automated, and how to measure progress in a way that matters.
Why Master Data Cleansing Projects Stall, and Why Yours Doesn’t Have To
Master data management and master data cleansing are related but not interchangeable. MDM is a long-term capability covering governance frameworks, data ownership, golden record policies, and platform infrastructure.
The master data cleansing process is something you can start this week. It is specifically designed to address data issues and data quality issues that impact business processes. The data cleansing process involves identifying what’s wrong with a defined dataset, fixing it systematically, and producing records that meet an agreed quality standard for a specific purpose. It does not require an MDM platform to be in place first.
By ensuring accurate and reliable data, the master data cleansing process directly supports decision making processes, enabling more informed and effective business operations.
The confusion between the data cleansing and master data management is the most common reason cleansing projects stall. A team may set out to clean customer master data when someone in governance notes that cleansing without ongoing stewardship will recreate the same problems in 18 months. That’s true, but it’s not an argument for delay as stewardship can be planned in parallel.
Another important thing that most teams overlook is that not all master data carries the same downstream risk. In a banking customer master, the records that matter most for regulatory reporting, AML screening, and credit decisioning represent a fraction of the total. A fit-for-purpose approach identifies which records and fields drive the most risk and cleans those first. When a cutover date or regulatory deadline is immovable, the most critical data is clean even if the entirety of the master data hasn’t been fully addressed.
The Five Core Master Data Cleansing Tasks, Ranked by Impact
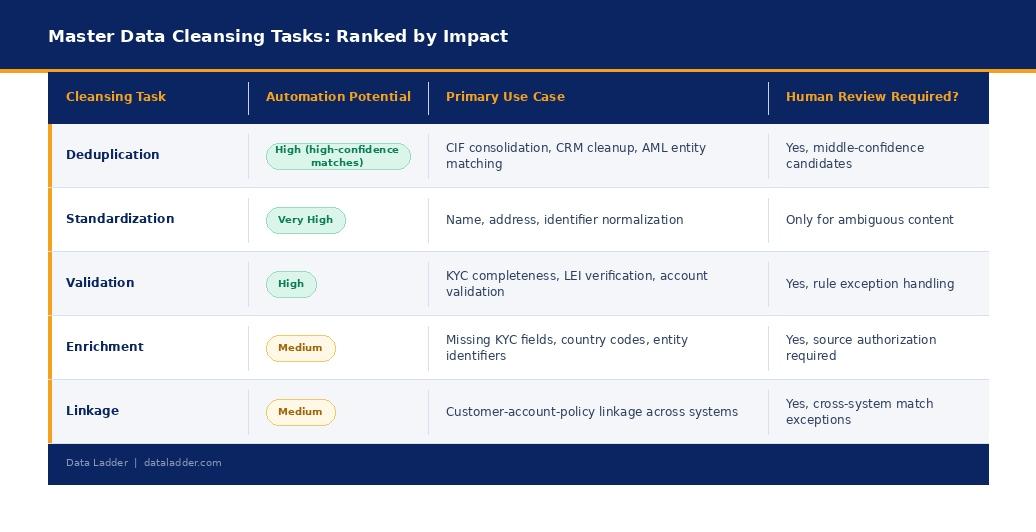
Deduplication is the highest-impact task because duplicate data often arises from multiple sources, creating compliance exposure and undermining data accuracy and data integrity, not just operational noise. A customer appearing under three different records may be screened against sanctions lists on one and missed on the others. Effective deduplication in financial services requires probabilistic and fuzzy matching, not just exact matching on name and date of birth. Names vary across legacy systems, addresses change, and entities operate under trading and legal names simultaneously which is why removing duplicate data and irrelevant data is essential.
Data standardization ensures consistency and accuracy, supporting data integration and reducing errors across systems. Luckily for most organizations, it also has the highest potential for automation. A name field containing “Mr. John Smith,” “JOHN SMITH,” and “Smith, John” across three records has a deterministic solution. Rule-based normalization addresses inconsistent formatting and handles the vast majority of format inconsistencies automatically, with ambiguous records flagged for human review.
Need your master data cleaned within days?
DataMatch Enterprise runs deduplication, standardization, and entity resolutions across source systems. Test on your own data and see your first match results in a week!
Start a Free TrialData validation is used to confirm that field values are correct according to defined rules and authoritative reference data, not just consistently formatted. Data cleansing tools like Data Match Enterprise validate and update data, reducing manual intervention and minimizing human errors. A postcode in the right format that doesn’t correspond to a real postcode may have passed standardization but failed validation. In regulated institutions, validation checks provide the documented evidence that quality standards were applied.
Data enrichment populates missing values from authoritative external sources such as address databases, entity registries, postcode reference files to enrich data and add relevant information. In financial services, data enrichment is most valuable for fields that affect regulatory completeness, such as country of residence for KYC or LEI for counterparty reporting. Every enriched field should have traceable provenance. Data enrichment fills missing values, improves data accuracy and completeness, and ensures that datasets contain relevant information for better decision-making.
Linkage connects related records across system boundaries, supporting data integration. Standardized data enhances integration across various systems and departments. A customer master, account system, and policy administration system may each contain records for the same individual. Without reliable linkage, those records can’t be combined into a coherent customer view, which is the underlying cause of most reporting failures and regulatory gaps in multi-system financial environments.
Data profiling is a critical first step in the cleansing process, involving the use of profiling tools to scan datasets for missing values, format discrepancies, and outliers. This helps identify anomalies, duplicate data, and irrelevant data before cleansing begins.
Modern data cleansing tools automate error detection and data quality assessments, reducing manual effort. Through these systematic cleansing steps, organizations achieve improved data quality for better decision-making and operational efficiency.
Scoping the Work to Match the Immediate Master Data Cleansing Need
The most reliable way to prevent a cleansing project from expanding indefinitely is to start with the use case, not the data. Migration cleansing, analytics cleansing, and regulatory reporting cleansing have different quality requirements across different fields and populations. Scoping the work helps identify and prioritize data issues and remove irrelevant data, ensuring that the cleansing process is focused and efficient. Scoping against the most demanding downstream use when the immediate use case is less demanding is the structural cause of most scope creep.
The most important step in mitigating the risk of wasting time and effort is defining the use case first. Once the use case is defined and understood, you can extract the data quality requirements from it. The next step is to scope the extent to which the data needs to be cleaned for the project at hand and then stop there.
Scope creep follows a predictable pattern: profiling reveals problems in adjacent domains, stakeholders note that fixing the target without fixing adjacent areas produces incomplete results, and the scope expands. Unified platforms can help maintain consistent information and keep the focus on relevant information during the cleansing process, reducing the risk of unnecessary expansion when not required for the immediate project at hand. This isn’t to say that cleaning all of your data isn’t necessary. It’s that certain fields and datasets need to be prioritized in the data cleansing process otherwise the project may continue being stalled.
A formal scope document with an explicit approval process for any additions is critical for a phased project. Delivering in increments and capturing out-of-scope findings as inputs to the next project is faster than trying to fix everything in one program.
Understanding What Can Be Automated in the Master Data Cleansing Process
Format standardization, high-confidence duplicate detection, and address validation can all be largely or fully automated. The exceptions such as middle-confidence merge decisions and survivorship rule exceptions require human review because the automated process can identify a potential problem but cannot make a reliable decision about the right resolution.
What makes those exceptions harder to predict in financial services is how the data is structured in practice. Customer names include legal entity suffixes (Ltd, plc, GmbH, Inc) that need to be stripped before comparison but preserved in the canonical record. The same entity may appear as “First Capital Ltd,” “First Capital Limited,” “First Capital,” and “FIRST CAP LTD” across four source systems, each carrying a different account ID. A fuzzy threshold applied to raw name strings won’t resolve that reliably. Rules that understand the relationship between trading names, registered names, and abbreviated forms are what get it right.
Date of birth fields present a similar configuration challenge. They’re used as a primary matching attribute in consumer financial data, but error rates in legacy core banking systems are higher than most data teams expect. Transposed digits, defaulted values (January 1st of the birth year is a common placeholder in older systems), and format inconsistencies across platforms mean DOB alone is an unreliable anchor. Match rules that weight it too heavily will miss true duplicates and incorrectly merge distinct individuals.
In insurance, the complexity compounds further. The same individual may appear as a policyholder, a beneficiary, a claimant, and a counterparty across different product lines and administration systems, each with different data entry conventions and varying field completeness. Linkage rules that connect these representations correctly require configuration that reflects how insurance data is actually structured across those systems.
This is why the line between what’s automated and what requires human review isn’t fixed. It depends on how well the matching rules are configured for the specific data domain before automation runs.
Ready to improve data matching in your environment?
DataMatch Enterprise ships with pre-built matching configurations for financial services including entity resolution and standardization across core financial systems.
Start a Free TrialGetting Master Data Management Decisions Made Without a New Governance Committee
The governance question that blocks more cleansing projects than any technical issue is who has the authority to approve a merge decision. This is the person who signs off that these two records are the same customer and this merged record is the one to keep. Effective data governance and adherence to defined rules are essential in this approval workflow to ensure consistency, accountability, and compliance.
In a bank, that touches the business line, risk and compliance, and technology simultaneously. Regulatory compliance is a key driver for maintaining audit trails, and effective data governance supports business operations by ensuring that data management processes meet industry standards and legal requirements. It doesn’t require a new committee. It requires a defined workflow that routes decisions to the right reviewer, captures approval, and records the basis for each decision.
The minimum audit trail for a cleansing decision captures four things: what the original records contained, what decision was made, what rule or review process produced it, and who approved it and when. In regulated institutions, this is what allows a data quality team to respond to a regulatory query with evidence rather than a general statement about program outcomes.
Five Data Quality Metrics That Prove It’s Working
Track these against a baseline established before cleansing begins and report them against defined targets throughout the program.

Master data cleansing doesn’t require a full MDM platform and doesn’t have to take months. The projects that deliver quickly define the use case before the scope, automate what can be automated, apply human review where it’s genuinely needed, and build only the governance structure required to get decisions made and documented.
The biggest obstacle is the assumption that the work has to be complicated. It doesn’t.
Preparing financial master data for a migration or analytics project?
Try Data Ladder on your own data to see how it profiles, deduplicates, and standardizes records without a lengthy implementation.
Start a Free TrialFAQ
What is master data cleansing in financial services?
It’s the process of identifying and correcting quality issues in core entity records (customers, accounts, counterparties, vendors) to meet a defined quality standard for a specific downstream use. Master data cleansing is essential when data is being integrated from various systems as it eliminates incorrect and inaccurate data that may arise from multiple sources. It’s a scoped, time-bounded intervention that doesn’t require a full MDM program to be in place first.
How long does master data cleansing take?
A well-scoped project focused on a single data domain can deliver initial results in two to four weeks. Timeline is driven by the quality of the initial profiling, the complexity of the deduplication review workflow, and the availability of business line reviewers. Tools like Data Match Enterprise allow you to get a clear picture of your data in as less as 30 minutes.
What’s the difference between master data cleansing and MDM?
MDM is a long-term organizational capability. Master data cleansing is a specific, time-bounded intervention. Cleansing can and should happen before a full MDM program is in place. It’s a prerequisite for MDM, not a byproduct of it.
Which data cleansing tasks can be automated?
Format standardization, high-confidence duplicate detection, and address validation can be largely or fully automated. Merge decisions at middle confidence thresholds and survivorship rule exceptions require human review because the automated process can identify a potential issue but can’t determine the correct resolution without domain knowledge.

