





























Last Updated on mars 29, 2022
L’appariement de produits est le processus qui consiste à faire correspondre des produits identiques provenant de diverses sources grâce à des technologies d’apprentissage profond. Dans un environnement concurrentiel, où les habitudes d’achat des clients ont considérablement changé, les détaillants sont obligés de développer une meilleure compréhension de leurs produits, de leurs prix, de leurs attributs et plus encore.
De plus, l’augmentation des volumes de données rend encore plus difficile pour les détaillants de maintenir l’exactitude de leurs données sur les produits. Les problèmes surviennent trop souvent lorsque les données proviennent de plusieurs vendeurs et fournisseurs, ce qui rend difficile pour les détaillants de garantir la qualité de leurs données. C’est pourquoi les solutions de gestion des données produit automatisées et basées sur l’apprentissage profond sont la clé de l’avenir des entreprises de vente au détail.
Voici tout ce que vous devez savoir sur la correspondance des produits et sur la façon dont elle peut être un facteur essentiel pour déterminer la précision et la qualité de vos rapports de vente et d’information commerciale.
Aller au-delà de la correspondance d’attributs de base
Traditionnellement, les détaillants utilisent des attributs tels que les UGS, les titres, les marques pour faire correspondre manuellement les produits. Non seulement cela prend du temps, mais c’est aussi contre-productif, d’autant plus que les données sur les produits sont des textes non structurés contenant des informations variables.
Les marques veulent que leurs produits soient représentés uniformément dans la bonne catégorie, mais les détaillants peuvent souvent ne pas placer le bon produit dans la bonne catégorie ou omettre complètement de présenter un attribut clé. Pour que la correspondance des produits fonctionne, les détaillants doivent extraire les attributs, supprimer les doublons, normaliser les informations et les classer par catégories afin de garantir une expérience utilisateur optimale. Sans ces contrôles, un utilisateur peut, par exemple, voir un ordinateur portable non tactile dans une recherche portant sur un « ordinateur portable tactile ». La correspondance des produits permet aux détaillants de classer les variations et de s’assurer qu’elles ne deviennent pas un problème en amont. Un utilisateur peut finir par acheter le mauvais produit si les catégories et les attributs ne sont pas clairement définis.
Aujourd’hui, la correspondance des produits a dépassé le stade de base. Des solutions modernes comme ProductMatch Enterprise permettent aux détaillants de nettoyer, normaliser et consolider des informations variables provenant de sources multiples afin de créer des informations produit unifiées. Tout le défi de la correspondance des produits réside dans l’extraction et la classification des attributs, en veillant à ce que les variations mineures soient identifiées au cours du processus.
Pourquoi l’appariement des produits est-il si difficile ?
Exactitude, précision et texte non structuré !
Pouvez-vous faire la différence entre les deux produits ?
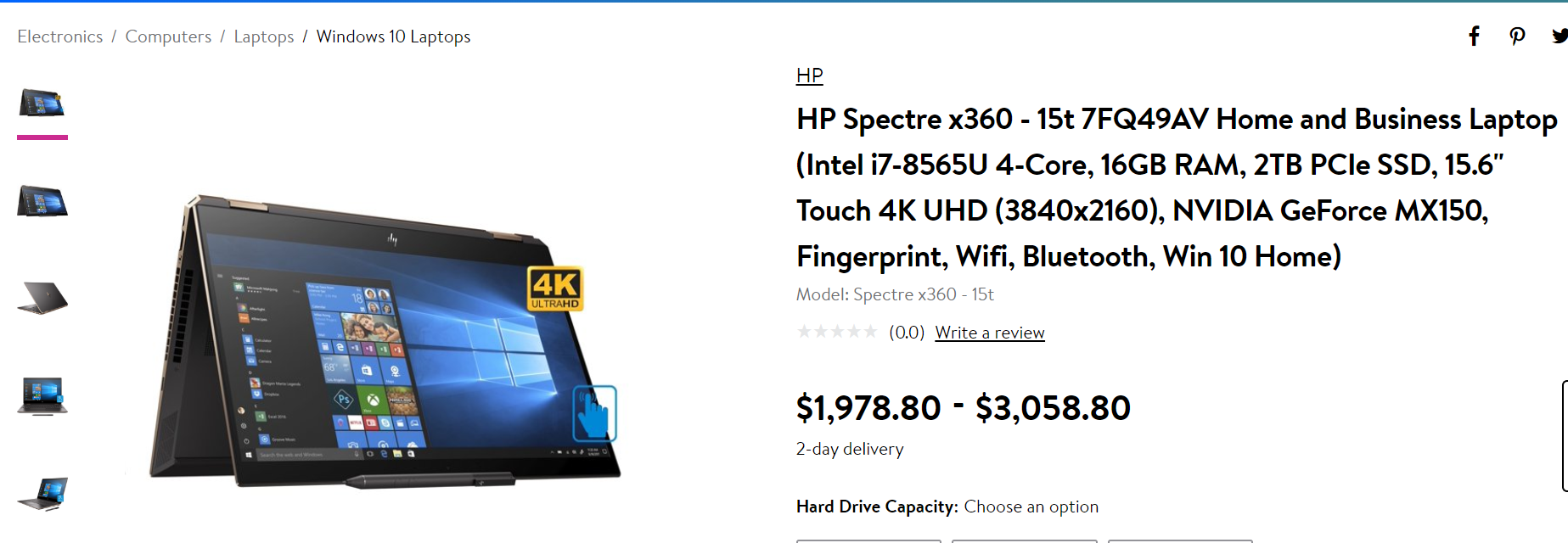
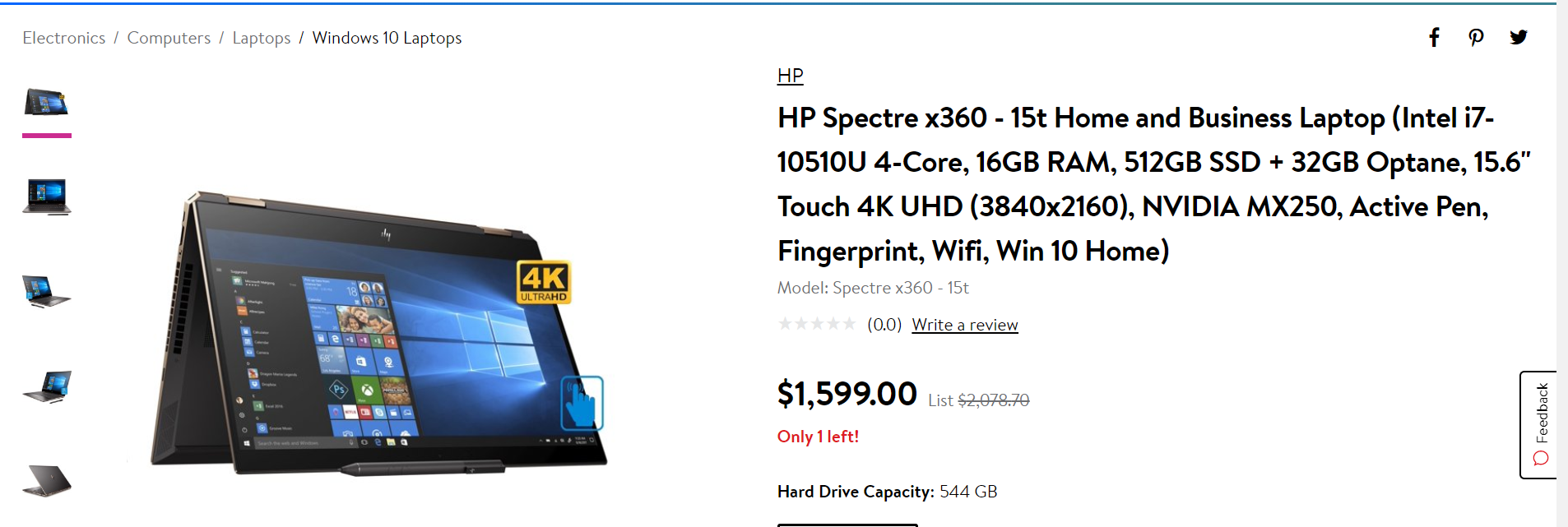
Vous avez remarqué qu’il s’agit de la même marque, du même modèle d’ordinateur portable, mais avec des attributs différents ? Si vous deviez faire correspondre ces produits sur la base de la marque, du nom ou du numéro du modèle, vous obtiendriez un faux positif pour une correspondance d’attribut. Pire encore, le client verrait l’annonce d’un SSD de 2 To au lieu d’un SSD de 512 Go. Ces variations mineures peuvent potentiellement affecter la crédibilité, les ventes et les performances marketing de votre site de vente au détail. Sans compter qu’elle a également un impact sur vos processus de gestion des catalogues et des stocks de produits.
L’une des principales raisons pour lesquelles la correspondance des produits est si difficile est la description textuelle. Voici la description textuelle du même produit sur trois sites différents – le site officiel de HP, Amazon et Walmart.
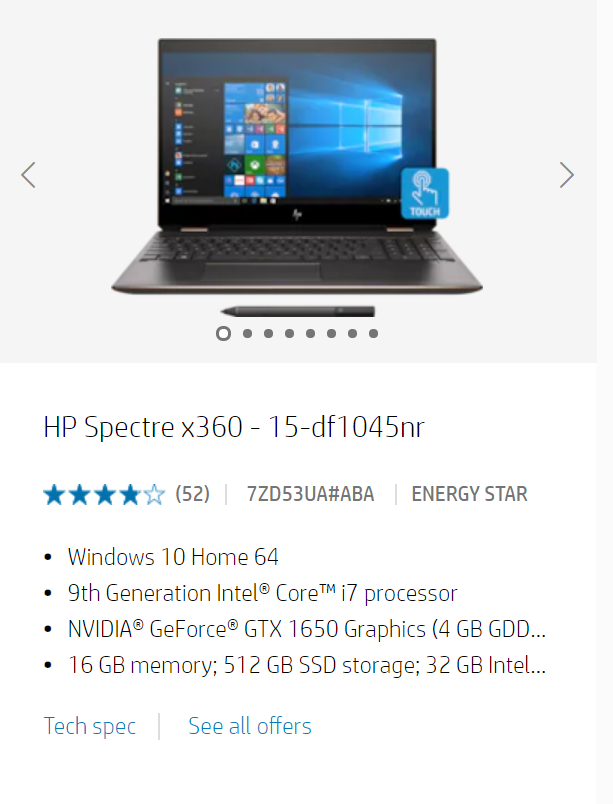
La même description ‘HP Spectre x360 – 15-df1045nr’ n’a pas donné lieu à un produit correspondant sur Walmart. Au lieu de cela, le mot clé a dû être modifié en HP Spectre x360 – 15 pour obtenir le résultat suivant :
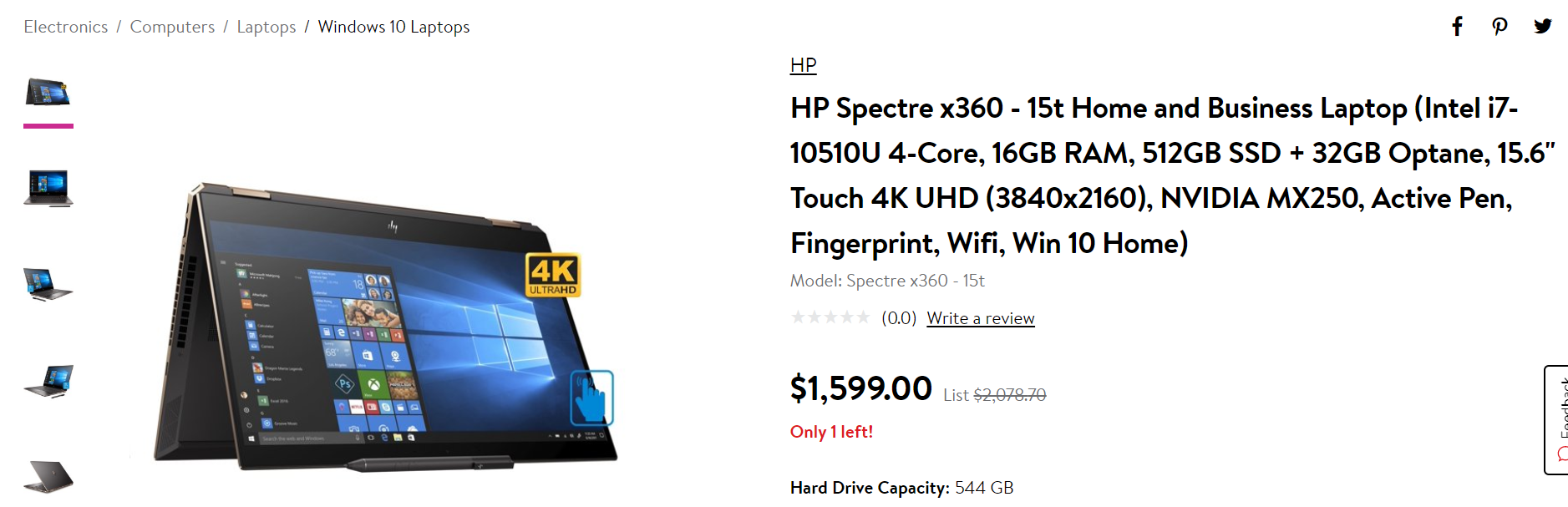
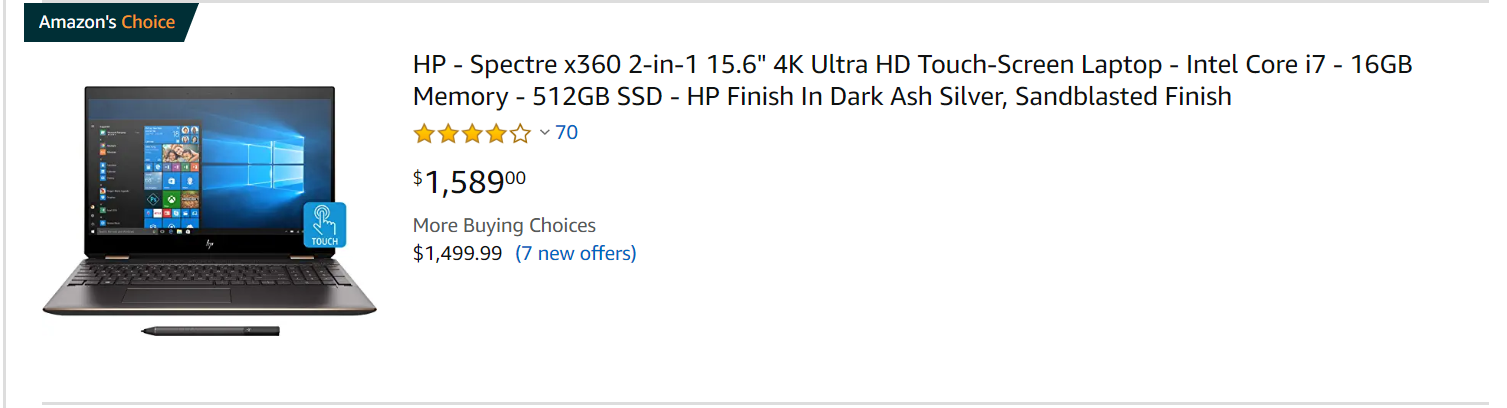
Chacune de ces plateformes propose des descriptions différentes pour un même produit. Si un détaillant devait acheter auprès de ces trois fournisseurs, il aurait du mal à faire correspondre les données.
Les données de produits sales ou bruyantes constituent un autre défi important. Les descriptions de produits peuvent comporter des balises, des valeurs d’attributs dénuées de sens ou irrégulières, et certaines peuvent contenir des informations incomplètes. Les données devraient être prétraitées pour s’ajuster aux normes définies avant que tout appariement réel puisse avoir lieu. Cela affecte également l’évolutivité lorsque le détaillant peut être amené à scanner un catalogue entier avec des informations variables pour détecter des paires de produits similaires.
Enfin, la qualité globale des données est une barrière difficile à franchir. Des descriptions variables, des normes irrégulières ou inexistantes (DHI665 ou DHI 665), des variations ou des erreurs d’orthographe (hoody, hoodie ou hood), des informations manquantes et des doublons font qu’il est extrêmement difficile pour les entreprises de vente au détail d’effectuer une comparaison efficace des produits.
Avantages de l’appariement des produits :
Dans un monde axé sur les données, où l’on attend des détaillants qu’ils gardent une longueur d’avance en temps réel, le rapprochement des produits présente de multiples avantages. Il aide les détaillants :
- Organiser les annonces sur une plate-forme de place de marché
- Découvrez les lacunes et les informations ou attributs manquants dans le catalogue de produits.
- Consolider des données produits variées provenant de plusieurs sources en une source unifiée
- Comparaison du cycle de vie des produits avec celui des concurrents
- Mettre en œuvre un cadre de qualité des données sur les produits afin de garantir l’exactitude des données sur lesproduits.
Compte tenu de sa criticité, la plupart des solutions de comparaison de produits s’efforcent de rendre cette comparaison précise, mais butent sur des erreurs humaines qui dégradent la qualité de l’information. Par exemple, la plupart des vendeurs ne suivent pas les directives d’Amazon concernant la rédaction des informations du catalogue de produits. La plupart des produits n’ont pas de code CUP, tandis que d’autres sont sans marque, ce qui rend difficile leur catégorisation. En l’absence de normes définies, les détaillants finissent par utiliser leurs propres identifiants, descriptions et noms d’attributs.
Tirer parti de l’apprentissage automatique et de l’intelligence artificielle
À l’heure actuelle, il serait impossible de faire correspondre avec précision les données relatives aux produits et de leur apporter une structure. Il s’agit d’un travail redondant qui doit être automatisé à l’aide de la technologie de la reconnaissance sémantique et de l’intelligence artificielle. ProductMatch de Data Ladder s’appuie sur les informations et les attributs historiques des produits qui sont constamment enrichis, ce qui permet aux détaillants de créer des taxonomies de produits, facilitant ainsi la catégorisation des produits.
ProductMatch utilise une combinaison d’algorithmes de correspondance propriétaires et flous pour identifier les produits au niveau des attributs tout en permettant le développement de hiérarchies de produits. ProductMatch est conçu pour gérer correctement les données non structurées, en veillant à ce que la gestion des données sur les produits fasse partie des processus d’entreprise afin d’en tirer des informations commerciales précieuses.
La qualité des données et la correspondance des produits vont de pair avec ProductMatch
Vous trouverez de multiples solutions de correspondance de produits qui tirent parti de l’apprentissage profond pour vous aider à analyser les catalogues en fonction des informations sur les produits, telles que le nom du produit, sa description, les valeurs des attributs, le prix et le nombre de variantes. Bien que cela soit très utile pour organiser votre catalogue de produits, cela n’aborde pas directement les problèmes sous-jacents de qualité des données qui rendent la correspondance des produits difficile.
Contrairement aux données sur les clients, les données sur les produits exigent précision et exactitude, deux qualités qui ne peuvent être obtenues sans la mise en œuvre d’un processus de qualité des données.
ProductMatch est donc une solution complète de qualité et de rapprochement des données produit qui permet aux entreprises de nettoyer, d’analyser, de normaliser, de catégoriser et de créer une version consolidée de leurs données pour un rapprochement exact et précis. Avec ProductMatch, vous serez en mesure de :
Nettoyer et normaliser les données sur les produits :
Les descriptions de produits doivent être décomposées en attributs, analysées et normalisées pour avoir un sens. ProductMatch permet aux utilisateurs de nettoyer les données en corrigeant les fautes de frappe dans les données non structurées, d’analyser les attributs pertinents à l’aide d’une correspondance de modèles avancée et d’appliquer des règles de normalisation à l’échelle.
Analyse intelligente des données :
Analysez avec précision les données en format libre pour séparer les champs tels que le titre du produit, les attributs clés, le nom du fabricant et le numéro de pièce en utilisant la technologie de reconnaissance sémantique.
Consolider les données provenant de sources multiples :
Les détaillants sont souvent confrontés à des informations variables provenant de sources multiples. Par exemple, dans un ERP, un produit est décrit comme étant le LCD Samsung 1080i Wi-Fi 32 pouces #2589-1 mais sur le site web, il pourrait simplement être LCD 32 pouces Wifi Samsung. Le même produit aura des descriptions différentes lorsqu’il sera exposé en magasin ou répertorié dans un catalogue. Avec une telle disparité, obtenir une vue d’ensemble claire des données sur les produits est un défi de taille. ProductMatch permet aux utilisateurs de connecter ces multiples sources de données et utilise la correspondance sémantique pour créer une source unique de vérité – comme indiqué ci-dessous :

Simplifier les données riches en attributs :
Les clients s’appuient sur un contenu solide pour prendre une décision d’achat et la simplification des données riches en attributs peut aider les détaillants à optimiser la recherche de produits, l’affinement de la recherche et la comparaison. Une taxonomie de produits solide peut établir des relations entre les produits tout en permettant au détaillant d’enrichir l’expérience d’achat de l’utilisateur. Sans compter que le fait d’obtenir des attributs au bon niveau de détail peut également favoriser le référencement et le trafic web vers les pages de détails et de listes de produits.
Avec ProductMatch, les détaillants peuvent mettre en œuvre un système complet de gestion des données produit, dont le coût est 80 % inférieur à celui des solutions PIM traditionnelles. D’après notre expérience, les détaillants qui ont amélioré la taxonomie des produits, les attributs et les données propres rapportent une augmentation de 2X du retour sur investissement et des ventes. Les entreprises qui vendent en ligne font état d’une augmentation de leur chiffre d’affaires de 10 à 25 % lorsqu’elles ajoutent des attributs de produit détaillés à leur catalogue en ligne existant, ce qui enrichit l’expérience de l’utilisateur et permet d’améliorer la satisfaction du client.
Pour toutes ces raisons, nous pensons que la correspondance des produits est le facteur clé de l’intelligence commerciale et marketing, à condition que la qualité des données sur les produits soit une priorité.
Vous voulez savoir comment nous pouvons vous aider à donner du sens à vos données produit ? Réservez une démonstration pour en savoir plus !



