































Last Updated on December 11, 2025
Product matching is the process of matching identical products from various sources through deep learning technologies. In a competitive landscape, where the customer’s spending habit has altered considerably, retailers are forced to develop a deeper understanding of their products, prices, attributes and more.
Additionally, expanding data volumes are making it even more challenging for retailers to keep up with the accuracy of their product data. Problems all too often arise with data streaming in from multiple vendors and suppliers, making it difficult for retailers to ensure the quality of their data. This is why automated, deep learning-based product data management solutions hold the key to the future of retail businesses.
Here’s everything you need to know about product matching and how it can be a critical factor in determining the accuracy and quality of your sales and market intelligence reports.
Going Beyond Basic Attribute Matching
Traditionally, retailers use attributes like SKUs, titles, brands to manually match products. Not only is this time consuming but also counterproductive especially since product data is unstructured text with varying information.
Brands want their products represented uniformly under the right category, but retailers may often miss placing the right product in the right category or they may miss presenting a key attribute entirely. For product matching to work, retailers must extract attributes, clean duplicates, standardize information and categorize it to ensure optimized user experience. Without these checks in place, a user, for instance, may see a non-touch laptop in a ‘touch laptop’ search. Product matching enables retailers to classify variations and ensure that they do not become a front-end problem. A user may end up buying the wrong product if categories and attributes are not clearly defined.
Today, product matching has gone beyond the basics. Modern solutions like ProductMatch Enterprise allows retailers to clean, standardize, consolidate varying information from multiple sources to create unified product information. The whole challenge to product matching lies in extracting and classifying attributes, ensuring that minor variations are identified in the process.
Why is Product Matching so Hard?
Accuracy, precision & unstructured text!
Can you tell the difference between the two products?
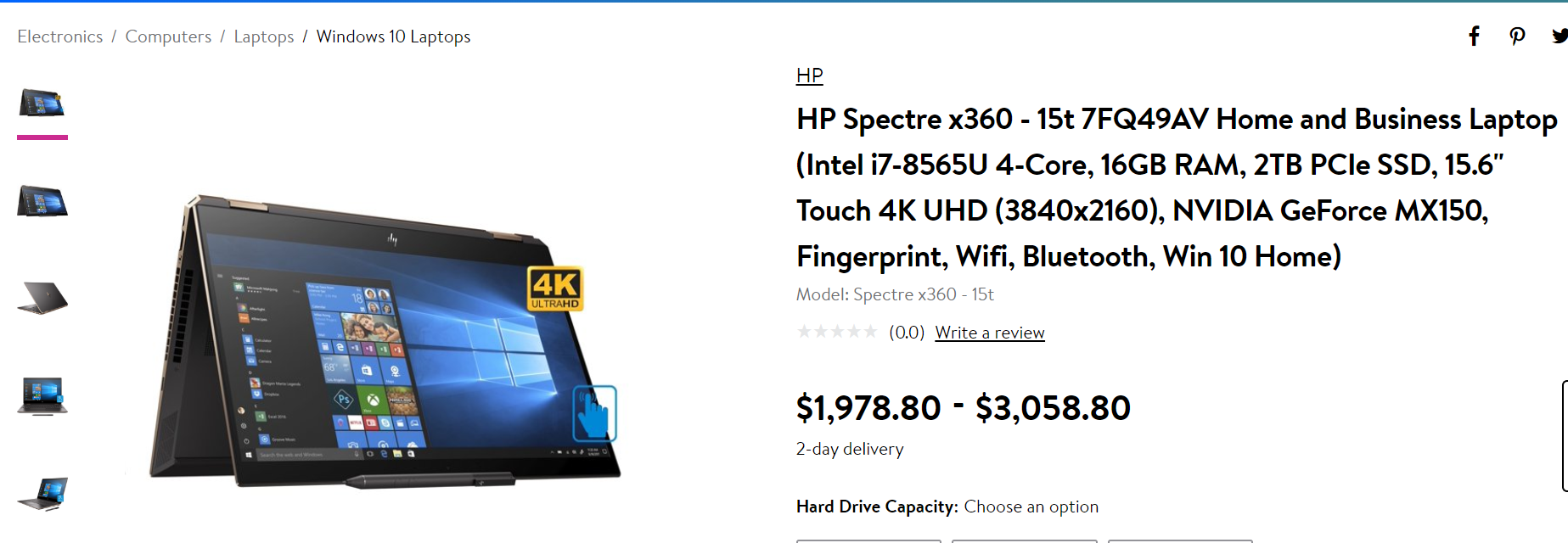
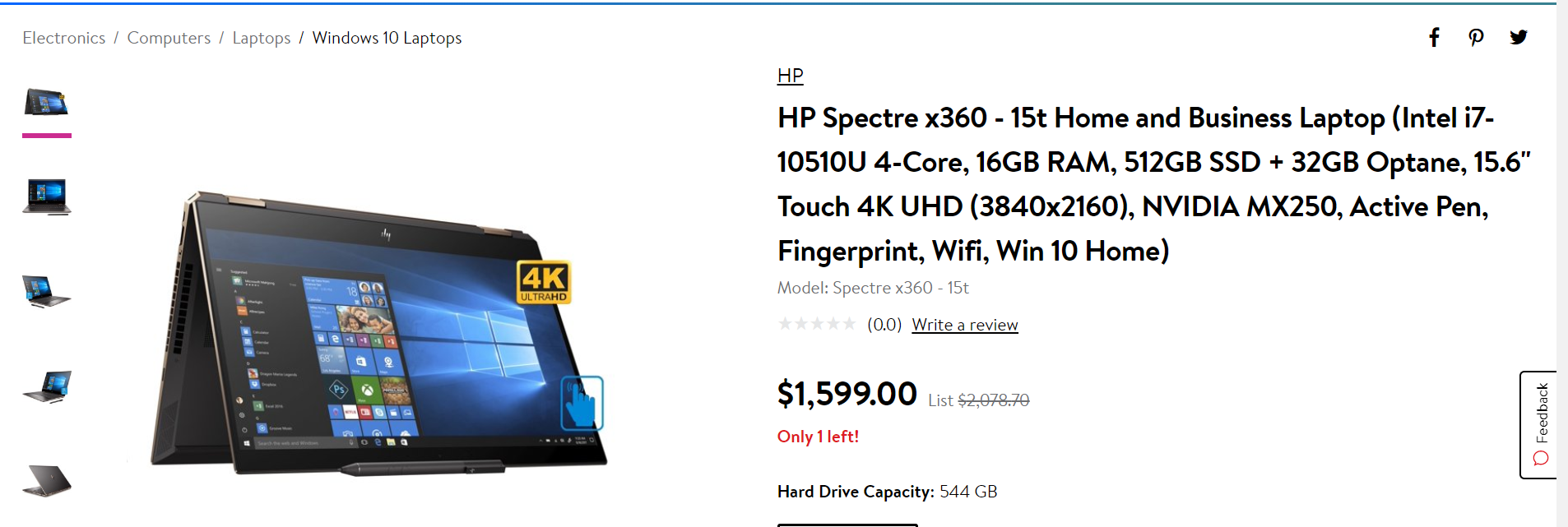
Notice how this is the same brand, same laptop model, but with varying attributes? Now if you were just to match these products based on brand, model names or model numbers, you’d be getting a false positive for an attribute match. Worse, the customer would see the listing for a 2TB SSD instead of a 512GB SSD. These minor variations can potentially affect your retail site’s credibility, sales and marketing performance. Not to mention, it also impacts your catalog and product inventory management processes.
One of the key reasons why product matching is so hard, is because of the text description. Here’s the text description of the same product across three different sites – HP’s official site, Amazon and Walmart.
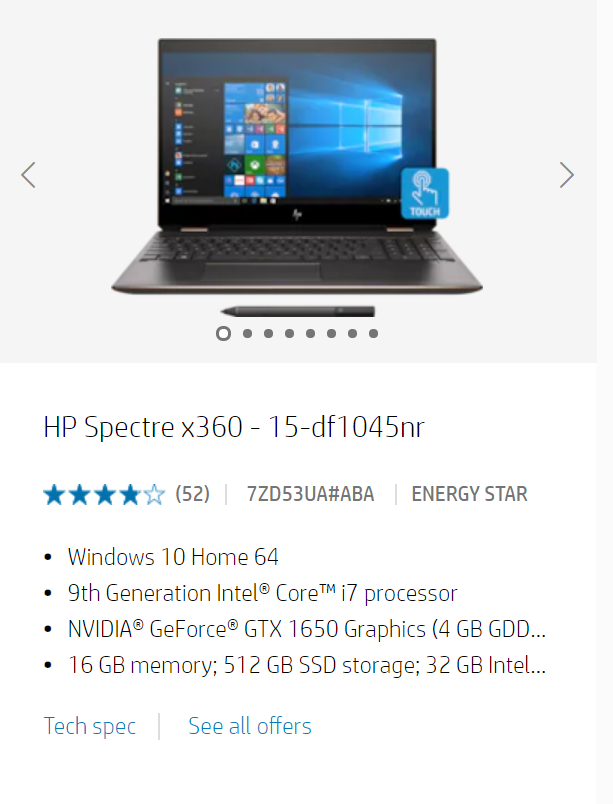
The same description ‘HP Spectre x360 – 15-df1045nr’ did not result in a matching product on Walmart. Instead, the keyword had to be revised to HP Spectre x360 – 15 to get the following result:
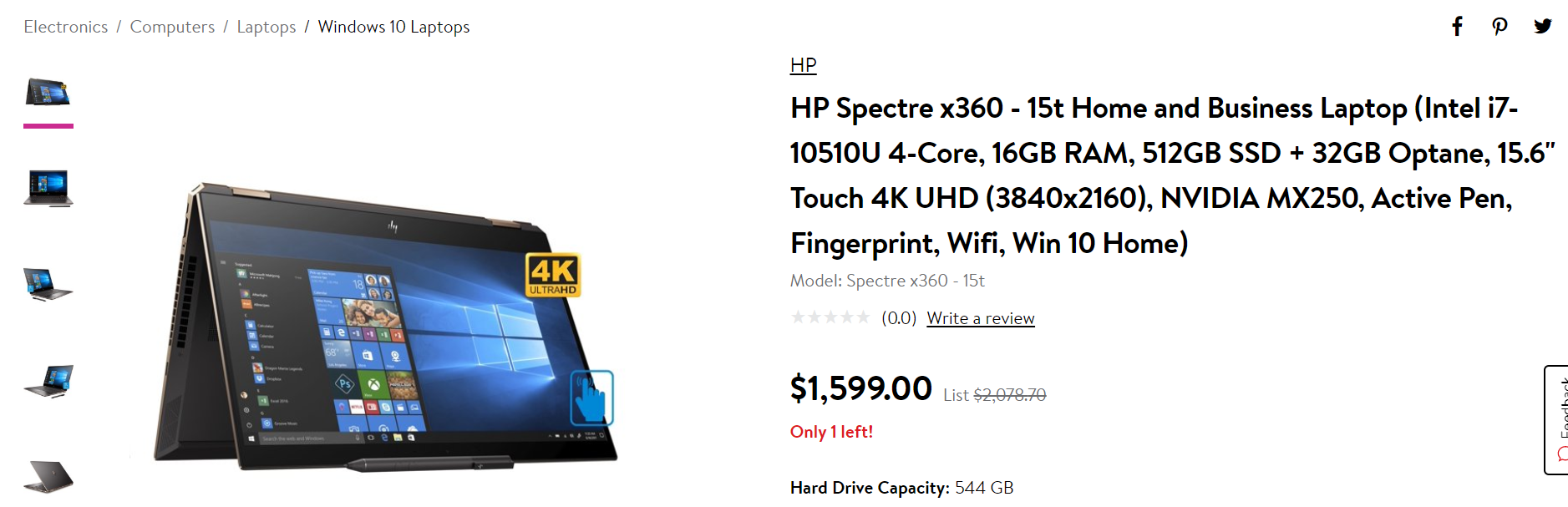
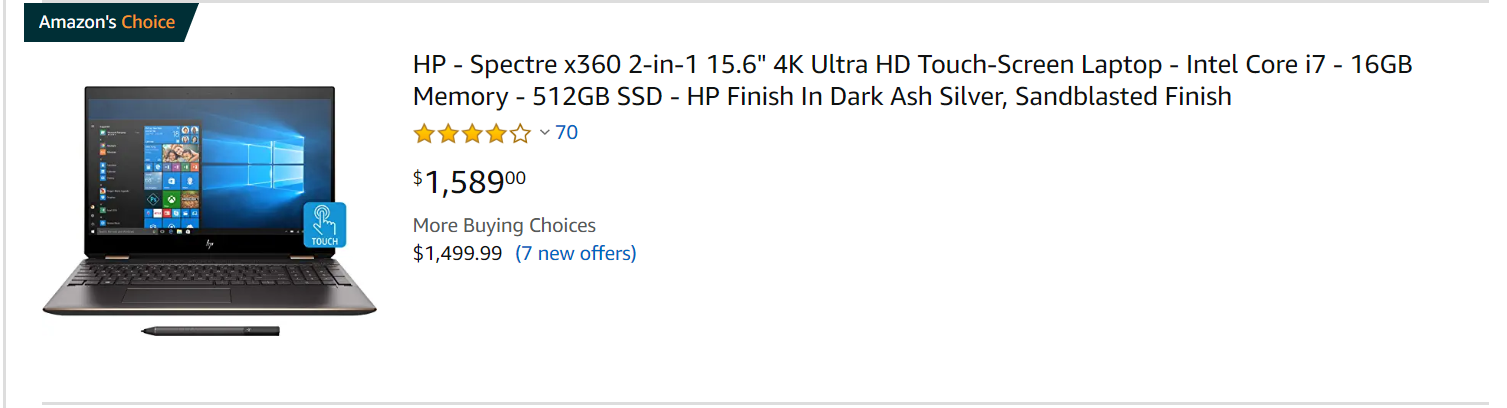
Each of these platforms has different descriptions for the same product. If a retailer were to buy from these three vendors, they’d have a hard time matching the data.
Another critical challenge is dirty or noisy product data. Product descriptions may have tags, meaningless or irregular attribute values, while some may have incomplete information. The data would have to be preprocessed to adjust to defined standards before any actual matching can take place. This also affects scalability where the retailer might have to scan an entire catalog with varying information to detect pairs of similar products.
Lastly, the overall data quality is a difficult barrier to cross. Varying descriptions, irregular or non-existent standards (DHI665 or DHI 665), spelling variations or errors (hoody, hoodie or hood), missing information, and duplicates make it extremely challenging for retail companies to perform effective product matching.
Benefits of Product Matching:
In a data-driven world where retailers are expected to stay ahead of the curve in real-time, product matching has multiple benefits. It helps retailers:
- Organize listings on a marketplace place platform
- Discover gaps and missing information or attributes in the product catalog
- Consolidate varying product data from multiple sources into a unified source
- Compares product life cycle across competitors
- Implement a product data quality framework to ensure product data accuracy
Given its criticality, most product matching solutions strive to make product matching accurate, but stumble because of human mistakes that degrade the quality of information. For instance, most sellers do not follow Amazon’s guidelines on writing product catalog information. Most products don’t have a UPC code, while others are unbranded making it difficult to categorize them. In the absence of defined standards, retailers end up using their own IDs, descriptions and attribute names.
Leveraging Machine Learning and Artificial Intelligence
In this day and age, it would be impossible to accurately match product data and bring structure to it. This is redundant work that needs to be automated with the help of semantic recognition and artificial intelligence technology. ProductMatch by Data Ladder builds on historical product information and attributes that are consistently enriched allowing retailers to create product taxonomies, thereby, making it easier to categorize products.
ProductMatch uses a combination of proprietary and fuzzy matching algorithms to identify products at an attribute level while also allowing the development of product hierarchies. ProductMatch is designed to get unstructured data right, ensuring product data management becomes part of enterprise processes to derive valuable business insights.
Data Quality and Product Matching Go Hand in Hand with ProductMatch
You’ll find multiple product matching solutions that leverage deep learning to help you scan catalogs based on product information such as product name, description, attribute values, price and variant counts. While this is quite helpful in organizing your product catalog, it doesn’t directly address the underlying data quality issues that make product matching challenging.
Unlike customer data, product data demands precision and accuracy, both of which cannot be achieved without implementing a data quality process.
Hence, ProductMatch is a full-fledged product data quality and matching solution that allows businesses to clean, parse, standardize, categorize and create a consolidated version of their data for accurate and precise data matching. With ProductMatch, you will be able to:
Clean and Standardize Product Data:
Product descriptions need to be broken down into attributes, parsed and normalized to make sense. ProductMatch allows users to clean up data by correcting typos in unstructured data, parse relevant attributes with advanced pattern matching, and apply standardization rules at scale.
Smart Data Parsing:
Parse free-form data accurately to separate fields like product title, key attributes, manufacturer name, and part number using semantic recognition technology.
Consolidate Data from Multiple Sources:
Retailers often struggle with varying information from multiple sources. For instance, in an ERP, a product is described as, Samsung 1080i Wi-Fi 32” LCD #2589-1 but on the website, it could just be LCD 32 inches Wifi Samsung. The same product will have different descriptions when displayed in-store or listed in a catalog. With this much disparity, getting a clear overview of product data is a significant challenge. ProductMatch allows users to connect these multiple sources of data and makes use of semantic matching to create a single source of truth – as given below:

Simplify Attribute-Rich Data:
Customers rely on robust content to make a buying decision and simplifying attribute-rich data can help retailers power product search, search refinement and comparison. A robust product taxonomy can establish relationships between products while also allowing the retailer to enrich the user shopping experience. Not to mention, getting attributes to the right level of detail can also drive SEO and web traffic to product detail and listing pages.
With ProductMatch, retailers can implement a complete product data management system, costing 80% less than traditional PIM solutions. From our experience, retailers that have improved product taxonomy, attributes and clean data report a 2X increase in ROI and sales. Companies that sell online report revenue increase between 10 and 25% when they added detailed product attributes to their existing online catalog, enriching user experience and enabling a boost in customer satisfaction.
For all these reasons, we believe product matching is the key factor to sales and marketing intelligence, provided, product data quality is prioritized.
Want to know how we can help you make sense of your product data? Book a demo to learn more!

