































Last Updated on December 23, 2025
In the previous blog The role of data quality in the world of retail, we discussed the role clean data plays in the retail industry and how retailers can identify if they have poor retail data quality. In this blog, we will look at what are master retail data assets, the most common issues present in retail data, and how to fix them.
Let’s get started.
What are master data assets in retail?
Every retail company utilizes a number of data assets to ensure successful operation of their business processes and transactions. They may differ depending on the type of company, but generally for a retail company, these include datasets for customers, prospects, leads, vendors, suppliers, products, locations, employees, stores, and so on. A few of them are considered to be master data assets since they are crucial for successful retail operation while the rest are somehow related to the master ones (either due to the similarity in meaning or data model). There are four main data assets that are used in almost every retail transaction, namely, customer, product, location, and sales.
Example of retail master data
As an example, consider the most common transaction that a retailer processes a number of times daily:
Customer A buys Product B from Location C.
This transaction in itself is considered a sales record. And for this transaction to be true, accurate, and reliable for use in any intended purpose, there must be a:
- Customer A in the customer dataset,
- Product B in the product dataset, and
- Location C in the location dataset.
Before we move on, take a look at a basic retail data model shown below:
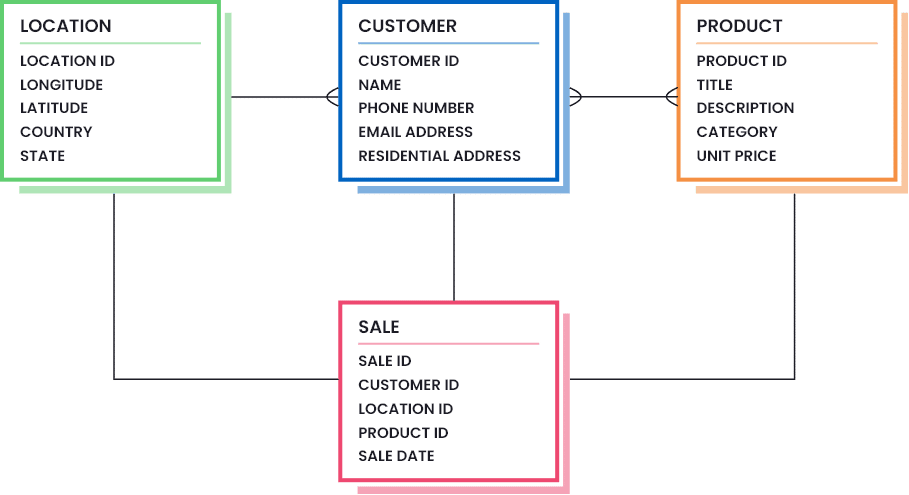
Common data quality issues in retail datasets and how to fix them
We discussed how data quality issues can cause irreversible damage to a retailer – including the impact on sales revenue, customer relationships, as well as brand reputation. Furthermore, we also looked at what master data is in the retail industry. In this section, we will try to see what poor data quality looks like in retail data, and what you can do to fix retail data quality issues.
Here, we will only focus on the data quality issues present in the four data assets mentioned above, that is, customer, product, location, and sales. This will help you to identify problems in other, similar datasets, for example, problems in the customer dataset are similar to the ones present in prospects, leads, suppliers, vendors, etc. Likewise, location datasets will have similar problems to store datasets, and so on.
Another thing to note here is that we will try to look at the issues that are specific to that type of data asset and not general data quality issues that are commonly found across all datasets. For that, we recently covered 12 most common data quality issues and where do they come from in our previous blog.
1. Customer
Customer information is one of the biggest assets for any organization. This is why businesses cannot afford to have missing, incorrect, or incomplete data in their customer datasets. But since customers interact with a brand across multiple channels, it is often the first place where discrepancies in data quality are detected. Let’s look at the three most common data quality issues faced by retailers in their customer datasets.
How to build a unified, 360 customer view
Download this whitepaper to learn about why it’s important to consolidate your data to get a 360 view.
Downloada. Duplicate customer records
What is it?
All interactions that a customer has with your brand during their buying journey are recorded somewhere in a database. These records may be coming from websites, landing page forms, social media advertising, sales records, billing records, marketing records, purchase point records and other such areas. If there’s no systematic way of identifying customer identities and merging new information with existing ones, you can end up with duplicates throughout your datasets.
It gets pretty difficult to track duplicates and identify the ones that belong to the same customer – especially if the data being captured is inconsistent across all channels, or there are obvious typos or variations present in duplicate records. As a result, you may end up sending the same email to a customer multiple times, or your team may experience problems while choosing one record for a customer that shows correct, up-to-date information about their phone number or address.
How to fix it?
To fix duplication, you will need to run advanced data matching algorithms that compare two or more records and calculate the likelihood of them belonging to the same customer. Sometimes, this comparison can be run using only one customer attribute (such as Social Security Number). In the absence of unique attributes, you will need to execute fuzzy matching on a combination of fields – such as using Customer Name, Residential Address, and Phone Number together.
Read more at The duplicate data dread – A guide to data deduplication.
b. Lack of 360 customer view
What is it?
An average organization with 200-500 employees uses about 123 SaaS applications these days. The vast number and variety of applications used to capture, manage, store, and use data is the main reason behind a customer’s information being scattered across sources. As a result, retailers fail to perform important statistical analysis that is needed to make better decisions, such as accurate marketing attribution or lead attribution.
A lack of 360 customer view may hinder your efforts to understand customer behavior and preferences, as well as offer smooth customer experiences.
How to fix it?
Deduplicating customer records mainly focuses on choosing one record of a customer and discarding others. On the other hand, enriching data to obtain a 360-customer view focuses on getting all data you have about a customer together, and inferring important meanings from that grouped information.
This is usually carried out through advanced data merge and survivorship rules in addition to data matching techniques. During data enrichment, you can define the kinds of interactions to retain in a customer’s record, and also create a golden record that acts as a single source of truth for everyone at the organization.
Read more at Your complete guide to obtaining a 360 customer view.
c. Unverified information
What is it?
Retailers capture customer information from all possible sources. These sources include – but are not limited to – website forms, over-the-counter surveys, POS, vendors, suppliers, and others. On top of that, data has a tendency to age very fast, whether a customer changed their residential address, an email address, or their last name due to their marital status. Such changes can cause you to have weeks or months old data that can very quickly become inaccurate or unverified.
How to fix it?
Since retailers have huge amounts of customer data, verifying all the information may seem impossible. It is best to start with a subset of information – maybe verifying the first 100 customers, or verifying only the names of first 1000 customers in the dataset. Performing verification on a subset of customer data will give you a good idea about how accurate your data is and what you can possibly do to fix unverified information.
Read more at What is data accuracy, why it matters and how companies can ensure they have accurate data.
2. Product
Product data is yet another crucial asset owned by retailers. Its importance can be gauged by the fact that it is the first thing that consumers browse or review in their buying journey. Therefore, any inaccuracy or discrepancy found in your showcased products can lead you to lose customers to competitors. Whether the information is used to sell products in your ecommerce store or to understand product placement in-store, ensuring good-quality product data can help you to gain a huge competitive advantage in the market.
Let’s look at the most common data quality issues found in product data and how you can fix them.
Kingfisher uses DataMatch Enterprise
See how Kingfisher corrects thousands of misclassified products by driving product hierarchies in unstructured format.
Read case studya. Duplicate product information
What is it?
Just like customer records, your product data is also prone to have multiple variations for the same product. Retailers usually use SKUs that uniquely identify every product, but depending on the source of information, SKUs might be absent or are present with varying formats – making it impossible to understand which products are actually duplicates.
When customers browse your website for a product and find multiple searches for something that looks almost identical, it is very likely that they will not feel comfortable buying from your store.
How to fix it?
Product duplication is fixed through the process of product matching. Products are compared with one another (in terms of titles, images, features, and other available attributes) to compute the likelihood of them being the same or similar. The same products are then merged together to enhance product information and offer more details about a product to visitors.
Read more at Product matching: The key factor to accurate sales and marketing intelligence.
b. Lack of product taxonomy
What is it?
Product taxonomy refers to a logical, hierarchal structure that helps to organize your products. When your products are logically organized, it makes product navigation, searchability, and access much easier. Oftentimes, retailers have the right products that are needed by customers, but still, they end up losing potential sales since the customers are not able to find the required goods quickly and efficiently. This is what happens when your products are not logically structured or lack taxonomy.
How to fix it?
Big retailers often hire taxonomists to categorize their products based on similar patterns or characteristics. However, not all retailers can afford to hire such professionals. They utilize self-service product categorization tools that analyze huge volumes of product information and intelligently categorize products into hierarchical structure.
Read more at Product taxonomy 101: Categorizing your store hierarchy to increase sales.
c. Lack of standardized product classification and naming
What is it?
Small-scale retailers perform product categorization or taxonomy internally, which means they create their own custom categories and classify products accordingly. On the other hand, retailers that trade globally require more standardized classification rules – not for categorizing products, but also for assigning them unique IDs or product numbers.
For example, consider product number 00121. This number follows the Standard International Trade Classification (SITC) product categorization system maintained by the UN. This standard uses a hierarchy that follows: division group – subgroup – heading.
How to fix it?
Instead of hiring resources to review global classification standards and manually classify and name each product in your inventory, it is best to use tools that support automatic categorization according to universally identified standards.
Read more at Classify product data: Classification standards and how to implement them painlessly.
3. Location
Location data is another important asset owned by retailers. Whether these are locations pinning your retail stores or customer addresses, it is imperative to have this data free from any data quality issue, such as missing information or unverified addresses.
Gibraltar Group uses DataMatch Enterprise
See how Gibraltar Group consolidates address silos to spearhead sales campaigns.
Read case studya. Unstandardized addresses
What is it?
Unstandardized addresses refer to the presence of unformatted, unstructured or semi-structured address information in your datasets. Standardization either refers to:
The structure of your addresses; for example, whether they span over multiple address fields or all information is present in one address field), or
The format of the values available in these fields; for example, states are abbreviated (NY) or properly spelled (New York).
How to fix it?
This data quality issue can be fixed using address standardization software. Address standardization (or address normalization) is the process of checking the format of addresses against an authoritative database – such as USPS in the US – and converting address information into acceptable, standardized format.
A standardized address is correctly spelled out, formatted, abbreviated, geocoded, as well as appended with accurate ZIP+4 values. Standardized address information is important to ensure reliable deliveries and shipment, and effective direct mail campaigns based on customer location.
Read more at A quick guide to address standardization and verification.
b. Unverified addresses
What is it?
How many times have you dispatched orders for customer delivery, only to have your delivery man spend hours in finding the address – and worse, failing to find it altogether because the specified address was not a valid, mailable location. This is what unverified addresses look like in your datasets.
How to fix it?
This data quality issue can be fixed using address verification techniques. Address verification is the process of running addresses against an authoritative database – such as USPS in the US – and validating the realness of the information. This process verifies that the address is a mailable, accurate, and valid location within the country for delivering mail.
The process usually starts with address standardization, then goes on to parsing, geocoding, and formatting, etc.
Read more at Think address verification is an option?
4. Sales
Let’s look at the final but just as important asset for a retailer – sales records. Since sales records track transactions, they often refer to one or more data entities in their transactional information, such as products, customers, locations, stores, etc. These records are very crucial to retail business since critical decisions are based on sales information, such as monitoring annual revenue and profit, as well as finding our recurring customers, bestselling products, customer preferences according to a certain time of the year, and so on.
Integrating Salesforce with DataMatch Enterprise
Improve business opportunities and customer experience by fusing the industry’s fastest data cleansing software with the industry’s leading CRM.
Download whitepapera. Lack of referential integrity
What is it?
Since sales records refer to other entities, one of the biggest data quality issues incurred in sales data is lack of referential integrity. Referential integrity means that data records are true to their referencing counterpart. Retailers probably store their sales records in a Sales table, and each record mentions which product was sold when that sale was made. So, you probably expect to find Sales IDs as well as Product IDs in the Sales table. But if a Sales record refers to Product IDs that don’t exist in the Product table, it’s obvious that your datasets lack referential integrity. These issues can lead your teams to create incorrect reports, ship incorrect products, or ship products to customers that don’t exist, and so on.
How to fix it?
To overcome this data quality issue, it is important to enforce relationship constraints (primary key, foreign key constraints) on your sales data model. But it is best to scrutinize referential integrity issues present currently in your dataset as well. This can be done using smart lookup formulae to ensure all referencing IDs in sales dataset exist in their respective datasets.
Wrap up
We went through quite a lot of details about data quality and what it means in the world of retail. From the benefits of clean data and indicators of poor data, to the exact nature of data quality issues encountered in retail business and how they can possibly be fixed. Having delivered data solutions to Fortune 500 clients for over a decade, we have encountered many leaders that enforce the importance of data quality solutions for successful retail business. This is why we have designed a solution that resolves almost all retail data quality issues efficiently.
Major retailer uses DataMatch Enterprise
See how a major wholesaler beats a two-year data merger project deadline by several months.
Read case studyOur solution DataMatch Enterprise offers robust data cleansing, standardization, matching, and various other solutions to enhance the quality of your product, customer, and transaction data, as well as verify and pinpoint customer addresses for fast order shipments, and reconcile unresolved customer identities to ensure correct invoicing.
To know more about how we can help, you can download a free trial today or book a demo with our experts.

