





























Last Updated on septembre 13, 2022
Dans le blog précédent Le rôle de la qualité des données dans le monde de la vente au détail, nous avons discuté du rôle que jouent les données propres dans le secteur de la vente au détail et de la manière dont les détaillants peuvent identifier si la qualité de leurs données est mauvaise. Dans ce blog, nous verrons ce que sont les données de base de la vente au détail, les problèmes les plus courants qu’elles présentent et comment les résoudre.
Commençons.
Que sont les actifs de données de base dans le commerce de détail ?
Chaque entreprise de vente au détail utilise un certain nombre de données pour assurer le bon fonctionnement de ses processus et transactions. Ils peuvent différer selon le type d’entreprise, mais généralement, pour une entreprise de vente au détail, il s’agit de jeux de données pour les clients, les prospects, les pistes, les vendeurs, les fournisseurs, les produits, les emplacements, les employés, les magasins, etc. Quelques-unes d’entre elles sont considérées comme des données de base, car elles sont essentielles à la réussite des opérations de vente au détail, tandis que les autres sont liées d’une manière ou d’une autre aux données de base (en raison de la similitude de leur signification ou de leur modèle de données). Quatre données principales sont utilisées dans presque toutes les transactions de détail, à savoir le client, le produit, le lieu et les ventes.
Exemple de données de base du commerce de détail
À titre d’exemple, considérons la transaction la plus courante qu’un détaillant traite un certain nombre de fois par jour :
Le client A achète le produit B sur le site C.
Cette transaction est en elle-même considérée comme un acte de vente. Et pour que cette transaction soit vraie, précise et fiable pour être utilisée dans n’importe quel but prévu, il doit y avoir un :
- Client A dans l’ensemble de données sur les clients,
- le produit B dans l’ensemble de données sur les produits, et
- Emplacement C dans l’ensemble de données d’emplacement.
Avant de poursuivre, examinons un modèle de données de base pour la vente au détail, illustré ci-dessous :
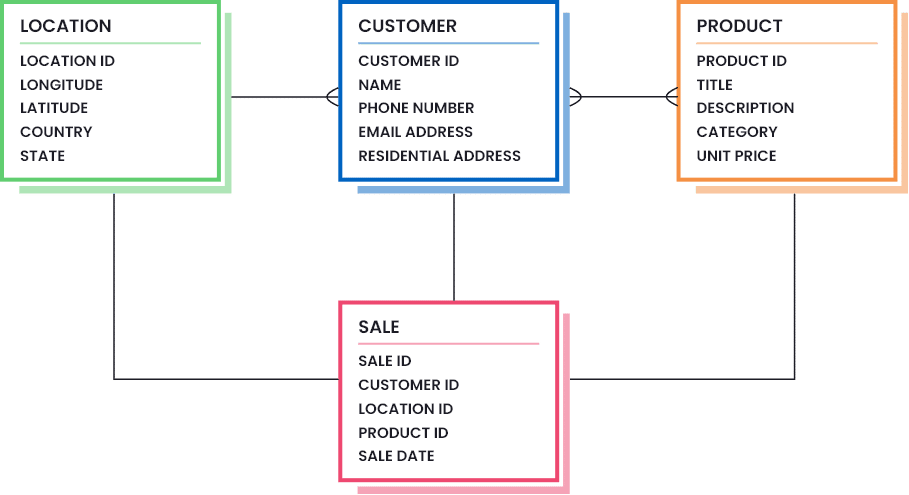
Problèmes courants de qualité des données dans les ensembles de données sur la vente au détail et comment les résoudre
Nous avons discuté de la façon dont les problèmes de qualité des données peuvent causer des dommages irréversibles à un détaillant – y compris l’impact sur le chiffre d’affaires, les relations avec les clients, ainsi que la réputation de la marque. En outre, nous avons également examiné ce que sont les données de base dans le secteur de la vente au détail. Dans cette section, nous allons essayer de voir à quoi ressemble la mauvaise qualité des données de détail, et ce que vous pouvez faire pour résoudre les problèmes de qualité des données de détail.
Nous nous concentrerons ici uniquement sur les problèmes de qualité des données présents dans les quatre actifs de données mentionnés ci-dessus, à savoir le client, le produit, le lieu et les ventes. Cela vous aidera à identifier les problèmes dans d’autres ensembles de données similaires. Par exemple, les problèmes dans l’ensemble de données du client sont similaires à ceux présents dans les prospects, les pistes, les fournisseurs, les vendeurs, etc. De même, les ensembles de données de localisation auront des problèmes similaires à ceux des ensembles de données de stockage, et ainsi de suite.
Il convient également de noter que nous nous efforcerons d’examiner les problèmes spécifiques à ce type de données et non les problèmes généraux de qualité des données que l’on retrouve dans tous les ensembles de données. Pour cela, nous avons récemment couvert les 12 problèmes de qualité des données les plus courants et leur origine dans notre blog précédent.
1. Client
Les informations sur les clients constituent l’un des principaux atouts de toute organisation. C’est pourquoi les entreprises ne peuvent pas se permettre d’avoir des données manquantes, incorrectes ou incomplètes dans leurs ensembles de données clients. Mais comme les clients interagissent avec une marque sur de multiples canaux, c’est souvent le premier endroit où les écarts de qualité des données sont détectés. Examinons les trois problèmes de qualité des données les plus courants auxquels sont confrontés les détaillants dans leurs ensembles de données clients.
How to build a unified, 360 customer view
Download this whitepaper to learn about why it’s important to consolidate your data to get a 360 view.
Downloada. Dossiers clients en double
Qu’est-ce que c’est ?
Toutes les interactions qu’un client a avec votre marque au cours de son parcours d’achat sont enregistrées quelque part dans une base de données. Ces enregistrements peuvent provenir de sites web, de formulaires de pages de renvoi, de publicités sur les médias sociaux, d’enregistrements de ventes, d’enregistrements de facturation, d’enregistrements de marketing, d’enregistrements de points d’achat et d’autres domaines similaires. S’il n’y a pas de moyen systématique d’identifier les identités des clients et de fusionner les nouvelles informations avec celles qui existent déjà, vous pouvez vous retrouver avec des doublons dans tous vos ensembles de données.
Il est assez difficile de repérer les doublons et d’identifier ceux qui appartiennent au même client, surtout si les données saisies ne sont pas cohérentes sur tous les canaux ou s’il y a des fautes de frappe ou des variations évidentes dans les enregistrements en double. En conséquence, vous pouvez vous retrouver à envoyer plusieurs fois le même courriel à un client, ou votre équipe peut rencontrer des problèmes en choisissant un enregistrement pour un client qui montre des informations correctes et à jour sur son numéro de téléphone ou son adresse.
Comment le réparer ?
Pour corriger les doublons, vous devrez exécuter des algorithmes avancés de rapprochement de données qui comparent deux ou plusieurs enregistrements et calculent la probabilité qu’ils appartiennent au même client. Parfois, cette comparaison peut être effectuée en utilisant un seul attribut du client (tel que le numéro de sécurité sociale). En l’absence d’attributs uniques, vous devrez exécuter une correspondance floue sur une combinaison de champs, par exemple en utilisant conjointement le nom du client, l’adresse résidentielle et le numéro de téléphone.
Pour en savoir plus, consultez le site The duplicate data dread – A guide to data deduplication.
b. Absence de vision à 360° du client
Qu’est-ce que c’est ?
Une entreprise moyenne de 200 à 500 employés utilise aujourd’hui environ 123 applications SaaS. Le grand nombre et la variété des applications utilisées pour saisir, gérer, stocker et utiliser les données sont la principale raison pour laquelle les informations d’un client sont dispersées entre plusieurs sources. Par conséquent, les détaillants n’effectuent pas les analyses statistiques importantes nécessaires pour prendre de meilleures décisions, comme l’attribution précise du marketing ou des pistes.
L’absence d’une vision à 360° du client peut entraver vos efforts pour comprendre le comportement et les préférences des clients, ainsi que pour leur offrir une expérience agréable.
Comment le réparer ?
La déduplication des enregistrements clients consiste principalement à choisir un enregistrement d’un client et à éliminer les autres. D’autre part, l’enrichissement des données pour obtenir une vue à 360° du client consiste à rassembler toutes les données dont vous disposez sur un client et à déduire des significations importantes de ces informations groupées.
Cela se fait généralement par le biais de règles avancées de fusion et de survie des données, en plus des techniques d’appariement des données. Au cours de l’enrichissement des données, vous pouvez définir les types d’interactions à conserver dans le dossier d’un client, et également créer un dossier d’or qui sert de source unique de vérité pour tous les membres de l’organisation.
Pour en savoir plus, consultez Votre guide complet pour obtenir une vue à 360° du client.
c. Informations non vérifiées
Qu’est-ce que c’est ?
Les détaillants recueillent des informations sur les clients à partir de toutes les sources possibles. Ces sources comprennent – sans s’y limiter – les formulaires de sites Web, les enquêtes en vente libre, les points de vente, les vendeurs, les fournisseurs et autres. En outre, les données ont tendance à vieillir très rapidement, qu’un client ait changé d’adresse résidentielle, d’adresse électronique ou de nom de famille en raison de son statut marital. Ces changements peuvent vous amener à disposer de données vieilles de plusieurs semaines ou mois qui peuvent très vite devenir inexactes ou non vérifiées.
Comment le réparer ?
Comme les détaillants disposent d’énormes quantités de données sur les clients, la vérification de toutes les informations peut sembler impossible. Il est préférable de commencer par un sous-ensemble d’informations – peut-être en vérifiant les 100 premiers clients, ou en vérifiant uniquement les noms des 1000 premiers clients de l’ensemble de données. La vérification d’un sous-ensemble de données clients vous donnera une bonne idée de la précision de vos données et de ce que vous pouvez éventuellement faire pour corriger les informations non vérifiées.
Pour en savoir plus, consultez la page Qu’est-ce que l’exactitude des données, pourquoi est-elle importante et comment les entreprises peuvent-elles s’assurer qu’elles disposent de données exactes.
2. Produit
Les données relatives aux produits constituent un autre actif crucial détenu par les détaillants. Son importance peut être mesurée par le fait qu’il s’agit de la première chose que les consommateurs parcourent ou examinent dans leur parcours d’achat. Par conséquent, toute inexactitude ou divergence constatée dans les produits que vous présentez peut vous faire perdre des clients au profit de vos concurrents. Que les informations soient utilisées pour vendre des produits dans votre magasin de commerce électronique ou pour comprendre le placement des produits en magasin, garantir des données de bonne qualité sur les produits peut vous aider à obtenir un avantage concurrentiel considérable sur le marché.
Examinons les problèmes de qualité de données les plus courants rencontrés dans les données de produits et la façon dont vous pouvez les résoudre.
Kingfisher uses DataMatch Enterprise
See how Kingfisher corrects thousands of misclassified products by driving product hierarchies in unstructured format.
Read case studya. Informations sur les produits en double
Qu’est-ce que c’est ?
Tout comme les dossiers des clients, vos données sur les produits sont également susceptibles de présenter de multiples variantes pour un même produit. Les détaillants utilisent généralement des UGS qui identifient chaque produit de manière unique, mais selon la source d’information, les UGS peuvent être absentes ou présentes dans des formats différents, ce qui rend impossible de comprendre quels produits sont en fait des doublons.
Lorsque des clients naviguent sur votre site web à la recherche d’un produit et qu’ils trouvent plusieurs recherches pour un produit qui semble presque identique, il est très probable qu’ils ne se sentent pas à l’aise pour acheter dans votre magasin.
Comment le réparer ?
La duplication des produits est corrigée par le processus d’appariement des produits. Les produits sont comparés les uns aux autres (en termes de titres, d’images, de caractéristiques et d’autres attributs disponibles) pour calculer la probabilité qu’ils soient identiques ou similaires. Les mêmes produits sont ensuite fusionnés pour améliorer les informations sur les produits et offrir plus de détails sur un produit aux visiteurs.
Plus d’informations sur le site Product matching : le facteur clé pour une intelligence commerciale et marketing précise.
b. Absence de taxonomie des produits
Qu’est-ce que c’est ?
La taxonomie des produits fait référence à une structure logique et hiérarchique qui permet d’organiser vos produits. Lorsque vos produits sont organisés de manière logique, la navigation, la recherche et l’accès aux produits sont beaucoup plus faciles. Souvent, les détaillants ont les bons produits dont les clients ont besoin, mais ils finissent par perdre des ventes potentielles car les clients ne sont pas en mesure de trouver les marchandises requises rapidement et efficacement. C’est ce qui se produit lorsque vos produits ne sont pas structurés logiquement ou manquent de taxonomie.
Comment le réparer ?
Les grands détaillants engagent souvent des taxonomistes pour classer leurs produits en fonction de modèles ou de caractéristiques similaires. Cependant, tous les détaillants n’ont pas les moyens d’engager de tels professionnels. Ils utilisent des outils de catégorisation de produits en libre-service qui analysent d’énormes volumes d’informations sur les produits et les classent intelligemment dans une structure hiérarchique.
Pour en savoir plus, consultez le site Product taxonomy 101 : Categorizing your store hierarchy to increase sales.
c. Absence de classification et de dénomination normalisées des produits
Qu’est-ce que c’est ?
Les petits détaillants effectuent la catégorisation ou la taxonomie des produits en interne, ce qui signifie qu’ils créent leurs propres catégories personnalisées et classent les produits en conséquence. D’autre part, les détaillants qui font du commerce à l’échelle mondiale ont besoin de règles de classification plus standardisées – non pas pour catégoriser les produits, mais aussi pour leur attribuer des identifiants ou des numéros de produits uniques.
Par exemple, prenons le numéro de produit 00121. Ce numéro suit le système de catégorisation des produits de la Classification internationale type du commerce (CTCI) géré par l’ONU. Cette norme utilise la hiérarchie suivante : groupe de division – sous-groupe – rubrique.
Comment le réparer ?
Au lieu d’engager des ressources pour examiner les normes de classification mondiales et classer et nommer manuellement chaque produit de votre inventaire, il est préférable d’utiliser des outils qui prennent en charge la catégorisation automatique selon des normes universellement identifiées.
Pour en savoir plus, consultez le site Classifier les données sur les produits : Les normes de classification et comment les mettre en œuvre sans difficulté.
3. Localisation
Les données de localisation constituent un autre actif important détenu par les détaillants. Qu’il s’agisse des emplacements de vos magasins de détail ou des adresses de vos clients, il est impératif que ces données soient exemptes de tout problème de qualité, comme des informations manquantes ou des adresses non vérifiées.
Gibraltar Group uses DataMatch Enterprise
See how Gibraltar Group consolidates address silos to spearhead sales campaigns.
Read case studya. Adresses non standardisées
Qu’est-ce que c’est ?
Les adresses non standardisées font référence à la présence d’informations d’adresses non formatées, non structurées ou semi-structurées dans vos ensembles de données. La normalisation se réfère soit à :
La structure de vos adresses ; par exemple, si elles s’étendent sur plusieurs champs d’adresse ou si toutes les informations sont présentes dans un seul champ d’adresse), ou
Le format des valeurs disponibles dans ces champs ; par exemple, les États sont abrégés (NY) ou correctement orthographiés (New York).
Comment le réparer ?
Ce problème de qualité des données peut être résolu par la normalisation des adresses. La normalisation d’adresses (ou normalisation d’adresses) est le processus qui consiste à vérifier le format des adresses par rapport à une base de données faisant autorité – comme l’USPS aux États-Unis – et à convertir les informations relatives aux adresses dans un format acceptable et normalisé.
Une adresse normalisée est correctement orthographiée, formatée, abrégée, géocodée, ainsi que complétée par des valeurs ZIP+4 précises. Il est important de disposer d’informations normalisées sur les adresses pour garantir la fiabilité des livraisons et des expéditions, ainsi que l’efficacité des campagnes de publipostage en fonction de l’emplacement du client.
Pour en savoir plus, consultez le guide rapide de la normalisation et de la vérification des adresses.
b. Adresses non vérifiées
Qu’est-ce que c’est ?
Combien de fois avez-vous expédié des commandes pour qu’elles soient livrées à vos clients, pour que votre livreur passe des heures à chercher l’adresse – et pire, qu’il ne la trouve pas parce que l’adresse spécifiée n’était pas valide et ne pouvait être envoyée. Voici à quoi ressemblent les adresses non vérifiées dans vos ensembles de données.
Comment le réparer ?
Ce problème de qualité des données peut être résolu en utilisant des techniques de vérification des adresses. La vérification des adresses consiste à comparer les adresses à une base de données faisant autorité – comme l’USPS aux États-Unis – et à valider l’authenticité des informations. Ce processus permet de vérifier que l’adresse est un lieu de distribution du courrier précis et valide dans le pays.
Le processus commence généralement par la normalisation des adresses, puis se poursuit par l’analyse syntaxique, le géocodage, le formatage, etc.
Plus d’informations sur le site Think address verification is an option ?
4. Ventes
Examinons le dernier atout, mais tout aussi important pour un détaillant : les registres des ventes. Étant donné que les enregistrements de ventes suivent les transactions, ils font souvent référence à une ou plusieurs entités de données dans leurs informations transactionnelles, telles que les produits, les clients, les emplacements, les magasins, etc. Ces enregistrements sont très importants pour le commerce de détail, car des décisions cruciales sont basées sur les informations relatives aux ventes, comme le suivi des recettes et des bénéfices annuels, ainsi que la recherche des clients récurrents, des produits les plus vendus, des préférences des clients en fonction d’une certaine période de l’année, etc.
Integrating Salesforce with DataMatch Enterprise
Improve business opportunities and customer experience by fusing the industry’s fastest data cleansing software with the industry’s leading CRM.
Download whitepapera. Manque d’intégrité référentielle
Qu’est-ce que c’est ?
Étant donné que les enregistrements de vente font référence à d’autres entités, l’un des principaux problèmes de qualité des données de vente est le manque d’intégrité référentielle. L’intégrité référentielle signifie que les enregistrements de données sont fidèles à leur contrepartie de référence. Les détaillants stockent probablement leurs enregistrements de ventes dans une table Sales, et chaque enregistrement mentionne quel produit a été vendu au moment où cette vente a été effectuée. Vous vous attendez donc probablement à trouver des identifiants de vente ainsi que des identifiants de produit dans la table des ventes. Mais si un enregistrement de ventes fait référence à des ID de produits qui n’existent pas dans la table des produits, il est évident que vos ensembles de données manquent d’intégrité référentielle. Ces problèmes peuvent conduire vos équipes à créer des rapports incorrects, à expédier des produits incorrects, ou à expédier des produits à des clients qui n’existent pas, etc.
Comment le réparer ?
Pour résoudre ce problème de qualité des données, il est important d’appliquer des contraintes de relation (clés primaires, clés étrangères) à votre modèle de données de vente. Mais il est préférable d’examiner également les problèmes d’intégrité référentielle présents actuellement dans votre ensemble de données. Cela peut être fait en utilisant des formules de consultation intelligentes pour s’assurer que tous les ID de référencement dans l’ensemble de données de vente existent dans leurs ensembles de données respectifs.
Récapitulation
Nous avons passé en revue de nombreux détails sur la qualité des données et ce qu’elle signifie dans le monde du commerce de détail. Qu’il s’agisse des avantages des données propres et des indicateurs de données médiocres, de la nature exacte des problèmes de qualité des données rencontrés dans le commerce de détail et de la façon dont ils peuvent être résolus. Après avoir fourni des solutions de données à des clients du Fortune 500 pendant plus de dix ans, nous avons rencontré de nombreux dirigeants qui soulignent l’importance des solutions de qualité des données pour la réussite des activités de détail. C’est pourquoi nous avons conçu une solution qui résout efficacement la quasi-totalité des problèmes de qualité des données de détail.
Major retailer uses DataMatch Enterprise
See how a major wholesaler beats a two-year data merger project deadline by several months.
Read case studyNotre solution DataMatch Enterprise offre des solutions robustes de nettoyage, de normalisation et de mise en correspondance des données, ainsi que diverses autres solutions permettant d’améliorer la qualité de vos données sur les produits, les clients et les transactions, mais aussi de vérifier et de localiser les adresses des clients pour accélérer l’expédition des commandes, et de rapprocher les identités des clients non résolues pour garantir une facturation correcte.
Pour en savoir plus sur la façon dont nous pouvons vous aider, vous pouvez télécharger un essai gratuit dès aujourd’hui ou réserver une démonstration avec nos experts.



