































Last Updated on December 29, 2025
In a world fascinated with the limitless opportunities of AI, ML, and predictive analysis, data quality has become a significant challenge. Businesses are on edge – they need accurate data to create customized experiences, but they don’t have the capacity to deal with bad data.
Enterprises must deal with two debilitating aspects of data quality, dirty data (duplicated data, spelling issues, incomplete info etc), and non-compliant data. This includes data that puts organizations at risk of GDPR violations, inaccurate analytics & flawed reports.
In this piece, we’ll focus on:
- Understanding the critical challenges with data quality
- Key data quality challenges businesses are having a hard time with
- Understanding the 3Ds with a Case Study
- How Data Ladder helps overcome these challenges
Let’s dive in.
Key Data Quality Challenges Businesses are Having a Hard Time With
Experts like to use, ‘garbage in, garbage out,’ to define the problem with data quality – however, there’s more to this.
A finding from OReilly’s State of Data Quality report states:
“Organizations are dealing with multiple, simultaneous data quality issues. They have too many different data sources and too much inconsistent data. They don’t have the resources they need to clean up data quality problems. And that’s just the beginning.”
The good news? Senior leadership in organizations are aware of this significant challenge.
The bad news? They lack the tools, resources, and solutions to solve this problem. Many are still struggling with basic data management processes.
In our experience with 4,500+ clients including those in the government and Fortune 500 companies, we often see three common problems:
- Data stored in multiple sources or disparate systems
- Data that does not meet quality objectives
- The lack of a robust data match solution that can weed out deeply buried duplicates
Businesses desperately need help handling disparate, dirty, duplicated data.
Understanding the 3Ds of Data
Dirty, disparate and duplicate data affects companies at a deeper level. They affect organizational processes & operational efficiency. They hamper efforts to build a data-driven culture & are the leading cause of flawed analytics and reports.
Disparate Data:
On average, an enterprise is connected to over 461 apps or systems. These systems collect data in multiple formats which is then dumped into a data lake. Companies that do not have data lakes attempt to add this data to their ERPs, but challenges with data formatting and mapping makes this a tedious process. As a result, the data is never sorted or treated until there is a critical and urgent need.
Take, for example, the case of Bell Bank – a renowned bank with a line of services spread across all 50 states of the U.S. As part of their core value to provide personalized customer experiences, the bank wanted to understand their customers better by evaluating their relationship and interaction at various touchpoints. To do this, they needed to create a single version of the truth for each of their customer. For this, the had to merge purge, dedupe, and clean millions of rows of data to finally get a consolidated picture of their customer’s journey.
But what exactly is disparate data sources? Is it just data stored in different sources?
Well no.
Disparate data is not only stored in different sources but also has different data formats, varieties in standards, and is usually considered low-quality data. The data is distinctly different in kind, quality, or character.
Bell Bank will have to derive data from marketing, sales, customer support, and third-party vendors just to get a clear picture of a customer’s profile, their interaction with the company, their household data, and much more. All of this ‘disparate’ data will have to be consolidated through a data matching process which will eventually give the bank its much-needed version of the truth.
Bell Bank is just one example of many companies, banks, retailers, and institutions that are realizing the importance of obtaining a singular customer view. In an age where customers demand personalized experiences even before asking for it, a consolidated view helps organizations be a step ahead. As Bell Bank understands the journey of its customer, it will be able to provide personalized services such as special loyalty cards, discounts, membership benefits etc. Disjointed data prevents companies from gaining this deeper insight, thus making it impossible for them to derive any value from their data.
Dirty Data
Keep all the problems with disparate data sources above and add in issues like:
- Incorrect spellings
- Incomplete information (address data without Zip Codes, missing digits in phone numbers etc)
- Use of punctuation in data fields
- Negative spacing
- Formatting problems
You’d think this was a simple thing to manage with filters and auto-corrects. But there are companies that do nothing but clean up physical street addresses in databases — because people use different terms for the street. (e.g. Street, St., ST). Their data analysts and specialists have to spend over 80% of their time fixing this raw data – the time and talent that was supposed to be for analysis and not fixing of spellings or abbreviations.
Unfortunately, data collected via websites and call centers are often rife with errors. Data pulled from social media sites are also problematic in terms of validity and accuracy. Data that is collected via human input is hardly ever clean. But to have a data analyst sit through millions of rows of data and make data fixing a permanent part of their job is not the solution.
Data cleaning is a constant need. This means your company needs an automated solution that will be monitored and operated by a data analyst or a business user, leaving them the necessary time to focus on deriving insights.
Duplicated Data
Duplicated data occurs when the same information is collected and stored in different data sources under different formats. And this happens at an alarmingly frequent rate.
Any time a user uses two emails to sign up a web form, a duplicate record is created. Any time, a data entry operator enters the wrong or a new unique ID key (like phone numbers or SSNs), a duplicate record is created. Any time a data source is not allowed to use SSNs, the chances of duplicates rise because the data operator has to assign their own unique keys to fields and when this record is supposed to be merged with another record, it causes a higher chance of duplication. Any time a system has a glitch, a duplicate can be created. In fact, there are just way too many possibilities for duplicates to be created easily.
Duplicated data is time-consuming to resolve. Companies make a classic mistake here – they think this can be resolved easily with trying different algorithms, but it’s much more complex. You can only weed out duplicates that have exact properties through traditional methods. You cannot weed out duplicates that seemingly share the same properties.
Take for example:
A customer, Catherine, writes name as Catherine Davis, Cath Davis, C. Davis at different places. Now, if she’s also changed her phone number or her email address at multiple times during the data entry process, the system has already created duplicates.
An algorithm working on exact matches can identify duplicates provided Catherine’s name is spelled the same way in another record.
But if there are other variations, it cannot catch the duplicate.
This is why, accuracy is critical when it comes to de-duping data.
You need a solution that can run matches for millions of rows of data, using a combination of algorithms (fuzzy, deterministic, soundex etc) to weed out even the least probable of cases. In this regard, Data Ladder’s solution DataMatch Enterprise’s accuracy is unrivaled.
How Does Data Ladder Help Companies in Handling these 3 Bad Guys?
Over the past decade, Data Ladder has been helping organizations make sense of their data. Using our proprietary matching solution, in combination with other data matching algorithms, we help businesses de-dupe data at the highest level of accuracy and speed.
We understand all too well the struggles organizations are facing today. Data is the new fuel, but for that data to help organizations meet their business goals, it needs to be clean, accurate & usable. Companies are still getting there as they begin to understand the problems with their data – but they need a solution that can solve these problems quickly, efficiently, smartly.
And here’s how Data Ladder helps.
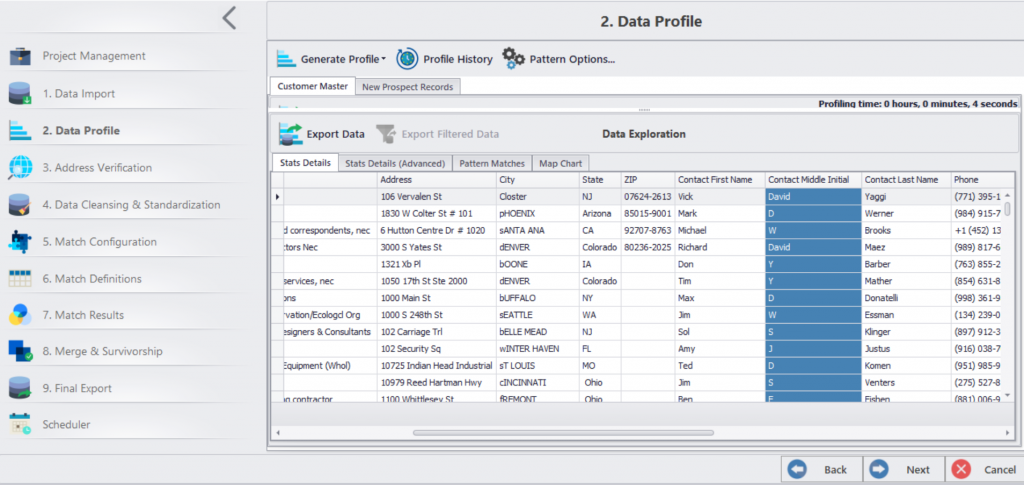
- We have a 7-stage framework starting from Data Integration and ending at Data Merger and Survivorship.
- You can integrate data from over 150+ applications on one platform.
- Following integration, you can clean, standardize, validate, and match data.
- You can create master records and merge data.
- Finally, you can automate data cleansing at a pre-scheduled date.
You need trusted data to achieve your big data analytics, migration, personalized customer experience & efficient business operation goals sooner.

